Дифференцирование логарифмической функции. Вычисление производных с помощью логарифмической производной. Применение логарифмической производной
Центральную тенденцию данных можно рассматривать не только, как значение с нулевым суммарным отклонением (средняя арифметическая) или максимальную частоту (мода), но и как некоторую отметку (определенный уровень анализируемого показателя), делящую ранжированные данные (отсортированные по возрастанию или убыванию) на две равные части. То есть половина исходных данных по своему значению меньше этой отметки, а половина – больше. Это и есть медиана . Мода и медиана — важные показатели, они отражают структуру данных и иногда используются вместо средней арифметической.
Итак, медианна – это уровень показателя, который делит некоторый набор данных на две равные половины. В качестве демонстрационного примера вновь обратимся к набору случайных чисел. Такое распределение при большом количестве значений в литературе описывается, как обыденное явление. Вот данные в виде рисунка.
Очевидно, что при симметричном распределении середина, делящая совокупность пополам, будет находиться в самом центре – там же, где средняя арифметическая (и мода). Это, так сказать, идеальная ситуация, когда мода, медиана и средняя арифметическая совпадают и все их свойства приходятся на одну точку – максимальная частота, деление пополам, нулевая сумма отклонений – все в одном месте. Однако, жизнь не так симметрична, как нормальное распределение. Поэтому посмотрим на ассиметричное распределение, и что там происходит с центральными нашими тенденциями.
Допустим, мы имеем дело с техническими замерами отклонений от ожидаемой величины чего-нибудь (содержания элементов, расстояния, уровня, массы и т.д. и т.п.). Если все ОК, то отклонения, скорее всего, будут распределены по закону, близкому к нормальному, примерно, как на рисунке выше (практика подобное предположение опровергает, ну да ладно). Но если в анализируемом процессе присутствует какой-то существенный и неконтролируемый фактор, то в наблюдениях могут появиться аномальные значения, которые в значительной мере повлияют на среднюю арифметическую, но при этом почти не затронут медиану, что отчетливо видно на следующей гистограмме.

Медиана – это основная альтернатива средней арифметической, т.к. она устойчива к аномальным отклонениям (выбросам). В этой статье рассказывается о том, как ведет себя средняя арифметическая при аномальных значениях и как с этим бороться, то есть как сделать ее менее зависимой от выбросов. Основные варианты – это увеличение числа наблюдений и/или устранение аномалий из аналитической выборки. Так вот, переход от средней арифметической к медиане – еще один способ получить устойчивую (робастную) оценку математичечского ожидания. Другое дело, что свойства средней арифметической будут навсегда потеряны, но тут надо смотреть, что важней.
Теперь примеры реального использования медианы в статистике. При анализе средней заплаты по стране вместо средней арифметической могут задействовать медиану. Народу не нравится, когда их собственная з/п оказывается ниже средней (арифметической) по стране. Это вызывает бурю эмоций и разоблачений в неправильных подсчетах. Мол, у меня зарплата 100 рублей, а у директора 1000 рублей, вот и получается в среднем по 550 рублей. Что такое , недовольным гражданам неведомо и не интересно. А вот если использовать медиану, то будет понятно, что половина населения получает доход меньше медианного значения, а половина – больше.
Этот показатель также применяется в демографической статистике, при анализе различных количественных и качественных характеристик (прочность материала, содержание элементов, время работы, количество отказов и проч.). Даже трейдеры на forex используют медиану, как некоторый секретный сигнал к началу действий. Хотя большинство из них это не спасает.
Математическим свойством медианы является то, что сумма абсолютных (по модулю) отклонений от медианного значения дает минимально возможное значение, если сравнивать с отклонениями от любой другой величины. Даже меньше, чем от средней арифметической, о как! Данный факт находит свое применение, например, при решении транспортных задач, когда нужно рассчитать место строительства объекта около дороги таким образом, чтобы суммарная длина рейсов до него из разных мест была минимальной (остановки, заправки, склады и т.д. и т.п.). Логистам и на заметку.
{module 111}
Формула медианы для дискретных данных чем-то напоминает формулу моды. А именно тем, что формулы как таковой нет. Медианное значение выбирают из имеющихся данных и только, если это невозможно, проводят несложный расчет.
Первым делом данные ранжируют (сортируют по убыванию). Далее есть два варианта. Если количество значений нечетно, то медианна будет соответствовать центральному значению ряда, номер которого можно определить по формуле:
№ Me – номер значения, соответствующего медиане,
N – количество значений в совокупности данных.
Тогда медиана будет обозначаться, как
Это первый вариант, когда в данных есть одно центральное значение. Второй вариант наступает тогда, когда количество данных четно, то есть вместо одного есть два центральных значения. Выход прост: берется средняя арифметическая из двух центральных значений:
![]()
Так происходит поиск или расчет в дискретных данных. Однако данные могут быть еще и интервальными , где выбрать конкретное значение не представляется возможным, так как конкретных значений просто нет. Как и в моде, медиану в таком случае рассчитывают по некоторому общепринятому правилу, исходя из определенного предположения, то есть на глазок. И нормально получается, я вам скажу!
Для начала (после ранжирования данных) находят медианный интервал . Это такой интервал, через который проходит искомое медианное значение. Определяется с помощью накопленной доли ранжированных интервалов. Где накопленная доля впервые перевалила через 50% всех значений, там и медианный интервал.
Не знаю, кто придумал формулу медианы, но исходили явно из того предположения, что распределение данных внутри медианного интервала равномерное (т.е. 30% ширины интервала – это 30% значений, 80% ширины – 80% значений и т.д.). Отсюда, зная количество значений от начала медианного интервала до 50% всех значений совокупности (разница между половиной количества всех значений и накопленной частотой предмедианного интервала), можно найти, какую долю они занимают во всем медианном интервале. Вот эта доля аккурат переносится на ширину медианного интервала, указывая на конкретное значение, именуемое впоследствии медианой.
Не мудрствуя лукаво, лучше обратимся к наглядной схеме – понятней будет.

Немного громоздко получилось, но теперь, надеюсь, все наглядно и понятно. Чтобы при расчете каждый раз не рисовать такой график, можно воспользоваться готовой формулой. Формула медианы имеет следующий вид:

где x Me - нижняя граница медианного интервала;
i Me - ширина медианного интервала;
∑f/2 - количество всех значений, деленное на 2 (два);
S (Me-1) - суммарное количество наблюдений, которое было накоплено до начала медианного интервала, т.е. накопленная частота предмедианного интервала;
f Me - число наблюдений в медианном интервале.
Как нетрудно заметить, формула медианы состоит из двух слагаемых: 1 – значение начала медианного интервала и 2 – та самая часть, которая пропорциональна недостающей накопленной доли до 50%. Чем-то даже похоже на формулу моды. Отличие заключается в поиске точки внутри интервала.
Для примера рассчитаем медиану по следующим данным.

Требуется найти медианную цену, то есть ту цену, дешевле и дороже которой по половине количества товаров. Для начала произведем вспомогательные расчеты накопленной частоты, накопленной доли, общего количества товаров. Теперь еще раз посмотрим, что у нас имеется.

По последней колонке «Накопленная доля» определяем медианный интервал – 300-400 руб (накопленная доля впервые более 50%). Ширина интервала – 100 руб. Теперь остается подставить данные в приведенную выше формулу и рассчитать медиану.
То есть у одной половины товаров цена ниже, чем 350 руб., у другой половины – выше. Все просто. Средняя арифметическая, рассчитанная по этим же данным, равна 355 руб. Отличие не значительное, но оно есть.
Расчет медианы в Excel
Статистика без автоматических расчетов – прошлый век. Медиану чисел легко найти, используя функцию Excel, которая так и называется — МЕДИАНА. Используется архипросто. Активируется ячейка для расчета, вызывается функция, выбирается диапазон данных и «ОК». Больше и обсуждать нечего. Годится и для четного, и для нечетного количества данных.
Другое дело интервальные данные. Соответствующей функции в Excel нет. Поэтому нужно задействовать приведенную выше формулу. Что поделаешь? Но это не очень трагично, так как расчет медианы по интервальным данным – редкий случай. Можно и на калькуляторе разок посчитать.
Кстати, тот факт, что медиана делит данные на две равные части, напоминает о некоторых методах группировки. Действительно, после нахождения медианы, мы также получаем две группы с равным количеством значений. Развивая эту идею, деление на группы можно производить не только по принципу 50/50, но и по другим долям. Например, 20% наибольших значений есть не что иное, как группа А в ABC-анализе . О других долях как-нибудь в другой статье. Видите, как пересекаются, казалось бы, не связанные методы?
Подходит к концу мой рассказ о статистическом показателе медиана. Надеюсь, он был неутомительным. Напоследок предлагаю задачку в стиле телевикторины «Кто хочет стать миллионером?». Имеется набор данных. 15, 5, 20, 5, 10. Каково среднее значение? Четыре варианта:
Предлагаю также посмотреть видеролик на тему расчета медианы в Excel.
Функция МЕДИАНА в Excel используется для анализа диапазона числовых значений и возвращает число, которое является серединой исследуемого множества (медианой). То есть, данная функция условно разделяет множество чисел на два подмножества, первое из которых содержит числа меньше медианы, а второе – больше. Медиана является одним из нескольких методов определения центральной тенденции исследуемого диапазона.
Примеры использования функции МЕДИАНА в Excel
При исследовании возрастных групп студентов использовались данные случайно выбранной группы учащихся в ВУЗе. Задача – определить срединный возраст студентов.
Исходные данные:
Формула для расчета:
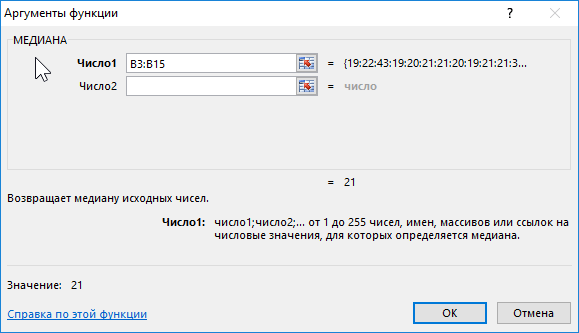
Описание аргумента:
- B3:B15 – диапазон исследуемых возрастов.
Полученный результат:

То есть в группе есть студенты, возраст которых меньше 21 года и больше этого значения.
Сравнение функций МЕДИАНА и СРЗНАЧ для вычисления среднего значения
Во время вечернего обхода в больнице каждому больному была замерена температура тела. Продемонстрировать целесообразность использования параметра медиана вместо среднего значения для исследования ряда полученных значений.
Исходные данные:

Формула для нахождения среднего значения:

Формула для нахождения медианы:

Как видно из показателя среднего значения, в среднем температура у пациентов выше нормы, однако это не соответствует действительности. Медиана показывает, что как минимум у половины пациентов наблюдается нормальная температура тела, не превышающая показатель 36,6.
Внимание! Еще одним методом определения центральной тенденции является мода (наиболее часто встречающееся значение в исследуемом диапазоне). Чтобы определить центральную тенденцию в Excel следует использовать функцию МОДА. Обратите внимание: в данном примере значения медианы и моды совпадают:

То есть срединная величина, делящая одно множество на подмножества меньших и больших значений также является и наиболее часто встречающимся значением в множестве. Как видно, у большинства пациентов температура составляет 36,6.
Пример расчета медианы при статистическом анализе в Excel
Пример 3. В магазине работают 3 продавца. По результатам последних 10 дней необходимо определить работника, которому будет выдана премия. При выборе лучшего работника учитывается степень эффективности его работы, а не число проданных товаров.
Исходная таблица данных:

Для характеристики эффективности будем использовать сразу три показателя: среднее значение, медиана и мода. Определим их для каждого работника с использованием формул СРЗНАЧ, МЕДИАНА и МОДА соответственно:

Для определения степени разброса данных используем величину, которая является суммарным значением модуля разницы среднего значения и моды, среднего значения и медианы соответственно. То есть коэффициент x=|av-med|+|av-mod|, где:
- av – среднее значение;
- med – медиана;
- mod – мода.
Рассчитаем значение коэффициента x для первого продавца:
Аналогично проведем расчеты для остальных продавцов. Полученные результаты:

Определим продавца, которому будет выдана премия:
Примечание: функция НАИМЕНЬШИЙ возвращает первое минимальное значение из рассматриваемого диапазона значений коэффициента x.
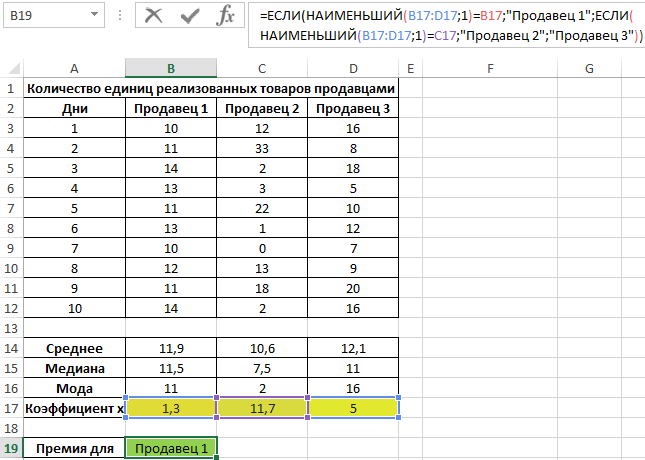
Коэффициент x является некоторой количественной характеристикой стабильности работы продавцов, которую ввел экономист магазина. С его помощью удалось определить диапазон с наименьшими отклонениями значений. Этот способ демонстрирует, как можно использовать сразу три метода определения центральной тенденции для получения наиболее достоверных результатов.
Особенности использования функции МЕДИАНА в Excel
Функция имеет следующий синтаксис:
МЕДИАНА(число1; [число2];...)
Описание аргументов:
- число1 – обязательный аргумент, характеризующий первое числовое значение, содержащееся в исследуемом диапазоне;
- [число2] – необязательный второй (и последующие аргументы, всего до 255 аргументов), характеризующий второе и последующие значения исследуемого диапазона.
Примечания 1:
- При расчетах удобнее передавать сразу весь диапазон исследуемых значений вместо последовательного ввода аргументов.
- В качестве аргументов принимаются данные числового типа, имена, содержащие числа, данные ссылочного типа и массивы (например, =МЕДИАНА({1;2;3;5;7;10})).
- При расчете медианы учитываются ячейки, содержащие пустые значения или логические ИСТИНА, ЛОЖЬ, которые будут интерпретированы как числовые значения 1 и 0 соответственно. Например, результат выполнения функции с логическими значениями в аргументах (ИСТИНА;ЛОЖЬ) эквивалентен результату выполнения с аргументами (1;0) и равен 0,5.
- Если один или несколько аргументов функции принимают текстовые значения, которые не могут быть преобразованы в числовые, или содержат коды ошибок, результатом выполнения функции будет код ошибки #ЗНАЧ!.
- Для определения медианы выборки могут быть использованы другие функции Excel: ПРОЦЕНТИЛЬ.ВКЛ, КВАРТИЛЬ.ВКЛ, НАИБОЛЬШИЙ Примеры использования:
- =ПРОЦЕНТИЛЬ.ВКЛ(A1:A10;0,5), поскольку по определению медиана – 50-я процентиль.
- =КВАРТИЛЬ.ВКЛ(A1:A10;2), так как медиана – 2-я квартиль.
- =НАИБОЛЬШИЙ(A1:A9;СЧЁТ(A1:A9)/2), но только если количество чисел в диапазоне является нечетным числом.
Примечания 2:
- Если в исследуемом диапазоне все числа распределены симметрично относительно среднего значения, среднее арифметическое и медиана для данного диапазона будут эквивалентны.
- При больших отклонениях данных в диапазоне («разбросе» значений) медиана лучше отражает тенденцию распределения значений, чем среднее арифметическое. Отличным примером является использование медианы для определения реального уровня зарплат у населения государства, в котором чиновники получают на порядок больше обычных граждан.
- Диапазон исследуемых значений может содержать:
- Нечетное количество чисел. В этом случае медианой будет являться единственное число, разделяющее диапазон на два подмножества больших и меньших значений соответственно;
- Четное количество чисел. Тогда медиана вычисляется как среднее арифметическое для двух числовых значений, разделяющих множество на два указанных выше подмножества.
В 1906 году великий ученый и известный специалист по евгенике Фрэнсис Гальтон посетил ежегодную выставку достижений животноводства и птицеводства в западной Англии, где совершенно случайно провел интересный эксперимент.
Как отмечает Джеймс Суровецки, автор книги «Мудрость толпы», на ярмарке Гальтона заинтересовало одно соревнование, в рамках которого люди должны были угадать вес забитого быка. Назвавший наиболее близкое к истинному число объявлялся победителем.
Гальтон был известен своим презрением к интеллектуальным способностям обычных людей. Он считал, что только настоящие эксперты смогут сделать точные утверждения о весе быка. А 787 участников соревнования не были экспертами.
Ученый собирался доказать некомпетентность толпы, вычислив среднее число из ответов участников. Каково же было его удивление, когда оказалось, что полученный им результат почти в точности соответствовал настоящему весу быка!
Среднее значение — позднее изобретение
Конечно, точность ответа поразила исследователя. Но еще более примечательным является тот факт, что Гальтон вообще догадался воспользоваться средним значением.
В сегодняшнем мире средние, и так называемые медианные показатели встречаются на каждом шагу: средняя температура в Нью-Йорке в апреле равняется 52 градусам по Фаренгейту; Стивен Карри в среднем зарабатывает 30 очков за игру; медианный семейный доход в США составляет $51 939/год.
Однако же идея о том, что множество различных результатов можно репрезентировать одним числом, довольна нова. До 17-ого века средние числа вообще не использовались.
Каким же образом появилась и развилась концепция средних и медианных значений? И как ей удалось стать главной измерительной методикой в наше время?
Преобладание средних значений над медианными имело далеко идущие последствия для на нашего понимания информации. И нередко оно приводило людей в заблуждение.
Среднее и медианное значения
Представьте, что вы рассказываете историю о четырех людях, ужинавших прошлым вечером с вами в ресторане. Одному из них вы бы дали 20 лет, другому — 30, третьему — 40, а четвертому — 50. Что вы скажете об их возрасте в своей истории?
Скорее всего, вы назовете их средний возраст.
Среднее значение часто используется для передачи информации о чем-либо, а также для описания некоего множества измерений. Технически, среднее значение — это то, что математики называют «средним арифметическим» — сумма всех измерений, разделенная на число измерений.
Хотя слово «среднее» (average) часто используется как синоним слова «медианное» (median), последним чаще обозначается середина чего-либо. Это слово происходит от латинского «medianus», что значит «середина».
Медианное значение в Древней Греции
История медианного значения берет свое начало с учения древнегреческого математика Пифагора. Для Пифагора и его школы медиана имела четкое определение и сильно отличалась от того, как мы понимаем среднее значение сегодня. Оно использовалось только в математике, а не в анализе данных.
В школе пифагорейцев медианное значение было средним числом в трехчленной последовательности чисел, находящемся в «равном» отношении с соседними членами. «Равное» отношение могло означать одинаково расстояние. Например, число 4 в ряду 2,4,6. Однако оно также могло выражать геометрическую прогрессию, например 10 в последовательности 1,10,100.
Статистик Черчилль Эйзенхарт объясняет, что в Древней Греции, медианное значение не использовалось в качестве репрезентирующего или заменяющего какой-либо набор чисел. Оно просто обозначало середину, и часто использовалось в математических доказательствах.
Эйзенхарт посвятил целых десять лет изучению среднего и медианного значений. Изначально он пытался отыскать репрезентирующую функцию медианы в ранних научных построениях. Однако вместо этого он обнаружил, что большинство ранних физиков и астрономов опирались на единичные, умело проведенные измерения, и у них не было методологии, позволявшей выбрать лучший результат среди множества наблюдений.
Современные исследователи основывают свои выводы на сборе больших объемов данных, как, например, биологи, изучающие человеческий геном. Древние ученые же могли провести несколько измерений, но выбирали лишь самое лучшее для построения своих теорий.
Как писал историк астрономии Отто Нойгебауэр, «это согласуется с осознанным стремлением античных людей минимизировать количество эмпирических данных в науке, потому что они не верили в точность непосредственных наблюдений».
Например, греческий математик и астроном Птолемей вычислил угловой диаметр Луны, используя метод наблюдения и теорию движения земли. Его результат был равен 31’20. Сегодня же мы знаем, что диаметр Луны колеблется от 29’20 до 34’6 в зависимости от расстояния от Земли. Птолемей в своих вычислениях использовал мало данных, но у него были все основания полагать, что они были точными.
Эйзенхарт пишет: «Необходимо иметь в виду, что связь между наблюдением и теорией в античности была иной, нежели сегодня. Результаты наблюдений понимались не как факты, под которые должна подстраиваться теория, но как конкретные случаи, которые могут быть полезны лишь в качестве иллюстративных примеров истинности теории»
В конце концов, ученые обратятся к репрезентативным измерениям данных, но изначально ни средние, ни медианные значения не использовались в этой роли. Со времен античности до сегодняшнего дня в качестве такого репрезентативного средства использовался другой математический концепт — полусумма крайних значений.

Полусумма крайних значений
Новые научные средства почти всегда возникают из необходимости решить определенную задачу в какой-либо дисциплине. Необходимость найти лучшее значение среди множества измерений возникло из потребности точно определить географическое положение.
Интеллектуальный гигант 11-ого века Аль-Бируни известен как один из первых людей, использовавших методологию репрезентирующих значений. Аль-Бируни писал, что когда в его распоряжении было множество измерений, и он хотел найти лучшее среди них, он использовал следующее «правило»: нужно отыскать число, соответствующее середине между двумя крайними значениями. При вычислении полусуммы крайних значений не принимаются во внимание все числа между максимальным и минимальным значениями, а находится среднее только для этих двух чисел.
Аль-Бируни применял этот метод в разных областях, в том числе для вычисления долготы города Газни, что находится на территории современного Афганистана, а также в своих исследованиях свойств металлов.
Однако в последние несколько веков полусумма крайних значений используется все реже. На самом деле, в современной науке она и вовсе не актуальна. На место полусуммы пришло медианное значение.
Переход к средним значениям
К началу 19-ого века использование медианного/среднего значения стало распространенным методом нахождения наиболее точно репрезентирующего значения из группы данных. Фридрих фон Гаусс, выдающийся математик своего времени, в 1809-ом году писал: «Считалось, что если некоторое число было определено несколькими прямыми наблюдениями, совершенными в одинаковых условиях, то среднее арифметическое значение является наиболее истинным значением. Если оно и не совсем строгое, то, по крайней мере, оно близко к действительности, и поэтому на него всегда можно положиться».
Почему произошел подобный сдвиг в методологии?
На этот вопрос довольно трудно ответить. В своем исследовании Черчилль Эйзенхарт предполагает, что метод нахождения среднего арифметического мог зародиться в области измерения магнитного отклонения, то есть в отыскании отличия между направлением стрелки компаса, указывающей на север, и реальным севером. Это измерение было крайне важным в эпоху Великих Географических Открытий.
Эйзенхарт выяснил, что до конца 16-ого века большинство измерявших магнетическое отклонение ученых использовали метод ad hoc (от лат. «к этому, для данного случая, для этой цели») при выборе наиболее точного измерения.
Но в 1580-ом году ученый Уильям Боро подошел к проблеме иначе. Он взял восемь различных измерений отклонения и, сравнив их, пришел к выводу, что наиболее точное значение было между 11 ⅓ и 11 ¼ градусами. Вероятно, он вычислил среднее арифметическое, которое находилось в этом диапазоне. Однако сам Боро открыто не называл свой подход новым методом.
До 1635-ого года вообще не было однозначных случаев использования среднего значения в качестве репрезентирующего числа. Однако именно тогда английский астроном Генри Геллибренд взял два различных результата измерения магнетического отклонения. Одно из них было сделано утром (11 градусов), а другое — днем (11 градусов и 32 минуты). Вычисляя наиболее истинное значение, он писал:
«Если мы найдем среднее арифметическое, мы с большой вероятностью можем утверждать, что результат точного измерения должен быть около 11 градусов 16 минут».
Вполне вероятно, что это был первый случай использования среднего значения как наиболее близкого к истинному!
Слово «среднее» (average) применялось в английском языке в начале 16-ого века для обозначения финансовых потерь от ущерба, которое получило судно или перевозимый груз во время плавания. В течение следующих ста лет оно обозначало именно эти потери, которые высчитывались как среднее арифметическое. Например, если корабль во время плавания был поврежден, и команде приходилось выбрасывать за борт некоторые товары, чтобы сохранить вес судна, инвесторы несли финансовые потери, эквивалентные сумме их инвестиции — эти потери вычислялись так же, как среднее арифметическое. Так постепенно значения среднего (average) и среднего арифметического сближались.
Медианное значение
В наши дни среднее значение или среднее арифметическое используются как основной способ для выбора репрезентативного значения множества измерений. Как же это произошло? Почему эта роль не была отведена медианному значению?

Френсис Гальтон был чемпионом медианного значения
Термин «медианное значение» (median) — средний член в ряде чисел, разделяющий этот ряд наполовину — появился примерно в то же время, что и среднее арифметическое. В 1599-ом году математик Эдвард Райт, работавший над проблемой нормального отклонения в компасе, впервые предложил использовать медианное значение.
«…Допустим, множество лучников стреляют в некоторую мишень. Цель впоследствии убирают. Каким образом можно узнать, где была цель? Нужно найти среднее место между всеми стрелами. Аналогично, среди множества результатов наблюдений ближе всего к истине будет то, которое находится посередине».
Медианное значение широко использовалось в девятнадцатом столетии, став обязательной частью любого анализа данных в то время. Им также пользовался и Френсис Гальтон, выдающийся аналитик девятнадцатого века. В истории о взвешивании быка, рассказанной вначале этой статьи, Гальтон изначально использовал медианное значение как представляющее мнение толпы.
Множество аналитиков, включая Гальтона, предпочитали медианное значение, поскольку его легче рассчитать для небольших наборов данных.
Тем не менее, медианное значение никогда не было более популярным, чем среднее. Скорее всего, это произошло из-за особых статистических свойств, присущих среднему значению, а также его отношения к нормальному распределению.
Связь среднего значения и нормального распределения
Когда мы проводим множество измерений, их результаты, как говорят статистики, «нормально распределены». Это значит, что если эти данные нанести на график, то точки на нем будут изображать нечто похожее на колокол. Если их соединить, получится «колоколообразная» кривая. Нормальному распределению соответствуют многие статистические данные, например, рост людей, показатель интеллекта, а также показатель самой высокой годовой температуры.
Когда данные нормально распределены, среднее значение будет очень близким к высшей точке на колоколообразной кривой, и очень большое количество измерений будет близким к среднему значению. Существует даже формула, предсказывающая, как много результатов измерений будут находиться на некотором расстоянии от среднего значения.
Таким образом, вычисление среднего значения дает исследователям много дополнительной информации.
Связь среднего значения со стандартным отклонением дает ему большое преимущество, ведь у медианного значения такой связи нет. Эта связь — важная часть анализа экспериментальных данных и статистической обработки информации. Именно поэтому среднее значение стало ядром статистики и всех наук, полагающихся в своих заключениях на множественные данные.
Преимущество среднего значения также связано с тем, что оно легко вычисляется компьютерами. Хотя медианное значение для небольшой группы данных довольно легко вычислить самостоятельно, все же намного проще написать компьютерную программу, которая находила бы среднее значение. Если вы пользуетесь Microsoft Excel, то наверняка знаете, что медианную функцию не так просто рассчитать, как функцию среднего значения.
В итоге, благодаря большому научному значению и простоте использования среднее значение стало главной репрезентативной величиной. Тем не менее, этот вариант далеко не всегда является самым лучшим.
Преимущества медианного значения
Во многих случаях, когда мы хотим вычислить центральное значение распределения, медианное значение является лучшим показателем. Так происходит потому, что среднее значение во многом определяется крайними результатами измерений.
Многие аналитики считают, что бездумное использование среднего значения отрицательно сказывается на нашем понимании количественной информации. Люди смотрят на среднее значение и думают, что это «норма». Но на самом деле оно может быть определено каким-нибудь одним сильно выдающимся из однородного ряда членом.
Представьте себе аналитика, желающего узнать репрезентативное значение для стоимости пяти домов. Четыре дома стоят $100,000, а пятый — $900,000. Среднее значение, таким образом, будет равняться $200,000, а медианное — $100,000. В этом, как и во многих других случаях, медианное значение дает лучшее понимание того, что можно назвать «стандартом».
Понимая, насколько сильно крайние значения могут сказаться на среднем, для отражения изменений в семейных доходах США используется медианное значение.
Медианные показатель также менее чувствителен к «грязным» данным, с которыми сегодня имеют дело аналитики. Многие статистики и аналитики собирают информацию, опрашивая людей в интернете. Если пользователь случайно добавит в ответ лишний ноль, который превратит 100 в 1000, то эта ошибка намного сильнее скажется на среднем значении, чем на медианном.
Среднее или медианное?
Выбор между медианным и средним значением имеет далеко идущие последствия — от нашего понимания влияния лекарств на здоровье до знаний относительно того, какой семейный бюджет можно назвать стандартным.
Поскольку сбор и анализ данных все больше определяет то, как мы понимаем мир, растет и значение используемых нами величин. В идеальном мире аналитики использовали бы и среднее, и медианное значение для графического выражения данных.
Но мы живем в условиях ограниченного времени и внимания. Из-за этих ограничений часто нам необходимо выбрать лишь что-то одно. И во многих случаях предпочтительней именно медианное значение.
Зарплат в различных отраслях экономики, температуру и уровень осадков на одной и той же территории за сопоставимые периоды времени, урожайность выращиваемых культур в разных географических регионах и т. д. Впрочем, средняя является отнюдь не единственным обобщающим показателем - в ряде случае для более точной оценки подходит такая величина как медиана. В статистике она широко применяется в качестве вспомогательной описательной характеристики распределения какого-либо признака в отдельно взятой совокупности. Давайте разберемся, чем она отличается от средней, а также чем вызвана необходимость ее использования.
Медиана в статистике: определение и свойства
Представьте себе следующую ситуацию: на фирме вместе с директором работают 10 человек. Простые работники получают по 1000 грн., а их руководитель, который, к тому же, является собственником, - 10000 грн. Если вычислить среднее арифметическое, то получится, что в среднем зарплата на данном предприятии равна 1900 грн. Будет ли справедливым данное утверждение? Или возьмем такой пример, в одной и той же больничной палате находится девять человек с температурой 36,6 °С, и один человек, у которого она равна 41 °С. Арифметическое среднее в этом случае равно: (36,6*9+41)/10 = 37,04 °С. Но это вовсе не означает, что каждый из присутствующих болен. Все это наталкивает на мысль, что одной средней часто бывает недостаточно, и именно поэтому в дополнение к ней используется медиана. В статистике этим показателем называют вариант, который расположен ровно посередине упорядоченного вариационного ряда. Если посчитать ее для наших примеров, то получится соответственно 1000 грн. и 36,6 °С. Другими словами, медианой в статистике называется значение, которое делит ряд пополам таким образом, что по обе стороны от нее (вниз или вверх) расположено одинаковое число единиц данной совокупности. Из-за этого свойства данный показатель имеет еще несколько названий: 50-й перцентиль или квантиль 0,5.

Как найти медиану в статистике
Способ расчета данной величины во многом зависит от того, какой тип вариационного ряда мы имеем: дискретный или интервальный. В первом случае, медиана в статистике находится довольно просто. Все, что нужно сделать, это найти сумму частот, разделить ее на 2 и затем прибавить к результату ½. Лучше всего будет пояснить принцип расчета на следующем примере. Предположим, у нас есть сгруппированные данные по рождаемости, и требуется выяснить, чему равна медиана.
Номер группы семей по кол-ву детей | Кол-во семей |
Проведя нехитрые подсчеты, получим, что искомый показатель равен: 195/2 + ½ = варианта. Для того чтобы выяснить, что это означает, следует последовательно накапливать частоты, начиная с наименьшей варианты. Итак, сумма первых двух строк дает нам 30. Ясно, что здесь 98 варианты нет. Но если прибавить к результату частоту третьей варианты (70), то получится сумма, равная 100. В ней как раз и находится 98-я варианта, а значит медианой будет семья, у которой есть двое детей.

Что же касается интервального ряда, то здесь обычно используют следующую формулу:
М е = Х Ме + i Ме * (∑f/2 - S Me-1)/f Ме, в которой:
- Х Ме - первое значение медианного интервала;
- ∑f - численность ряда (сумма его частот);
- i Ме - величина медианного диапазона;
- f Ме - частота медианного диапазона;
- S Ме-1 - сумма кумулятивных частот в диапазонах, предшествующих медианному.
Опять же, без примера здесь разобраться довольно сложно. Предположим, есть данные по величине
Зарплата, тыс. руб. | Накопленные частоты |
|
Чтобы воспользоваться вышеприведенной формулой, вначале нам нужно определить медианный интервал. В качестве такого диапазона выбирают тот, накопленная частота которого превышает половину всей суммы частот или равна ей. Итак, разделив 510 на 2, получаем, что этому критерию соответствует интервал со значением зарплаты от 250000 руб. до 300000 руб. Теперь можно подставлять все данные в формулу:
М е = Х Ме + i Ме * (∑f/2 - S Ме-1)/f Ме = 250 + 50 * (510/2 - 170) / 115 = 286,96 тыс. руб.
Надеемся, наша статья оказалась полезной, и теперь вы имеете ясное представление о том, что такое медиана в статистике и как ее следует рассчитывать.





