Найти объем выборки. Формула выборки - простая. «Определение необходимого объёма выборки»
Точность -- степень ошибочности результатов обследования или размер доверительного интервала.
Абсолютная точность задается определенным интервалом, в котором должно находиться оцениваемое значение.
Относительная точность определяется относительно уровня оценки параметра.
Достоверность -- степень уверенности в том, что оценка близка к истинному значению.
При определении объема выборки следует принимать во внимание некоторые качественные факторы: важность принимаемого решения, характер исследования, количество переменных, характер анализа, объемы выборки, которые использовались в подобных исследованиях, коэффициент охвата, коэффициент завершенности, а также ограниченность ресурсов. Статистически определенный объем выборки -- это чистый, или конечный, объем выборки, т.е. единицы совокупности, остающиеся после исключения потенциальных респондентов, которые не отвечают заданным критериям или не закончили интервью. В зависимости от коэффициентов охвата и завершенности может потребоваться намного больший объем исходной выборки. В коммерческих маркетинговых исследованиях недостаток времени, денег и хороших специалистов может иметь решающее значение при определении объема выборки. В проекте исследования постоянных покупателей универсального магазина объем выборки определялся именно по этим соображениям.
Метод доверительных интервалов:
Определение объема выборки методом доверительных интервалов основано на их создании вокруг выборочного среднего или выборочной доли с использованием формулы стандартной ошибки. В качестве примера предположим, что исследователь с помощью простого случайного отбора сформировал выборку из 300 семей для того, чтобы оценить ежемесячные расходы семьи на покупки в универмаге, и определил, что средний ежемесячный расход семьи в выборке равен 182 долл. Предыдущие исследования показали, что среднеквадратичное отклонение расходов в исследуемой совокупности равно 55 долл.
Мы хотим найти интервал, в который попадал бы определенный процент выборочных средних. Предположим, мы хотим определить интервал вокруг среднего значения совокупности, который включал бы 95% выборочных средних, опираясь на выборку из 300 семей; 95% выборочных средних можно разделить на две равные части, половина меньше и половина больше среднего, как показано на рис. 1. Вычисление доверительного интервала включает определение области меньше (XL) и больше (ХU) среднего значения (X) величины расходов.
Значения коэффициента z, соответствующие XL и ХU, можно рассчитать следующим образом:
Следовательно, минимальное значение X определяется как
а максимальное значение
Теперь установим 95%-ный доверительный интервал вокруг выборочного среднего, равного 182 долл. Для начала мы вычислим стандартную ошибку среднего:
Центральные 95% нормального распределения находятся в пределах?1,96 значений коэффициента z; 95%-ный доверительный интервал определяется как
Таким образом, 95%-ный доверительный интервал простирается от 175,77 до 188,23 долл. Вероятность нахождения истинного среднего значения наблюдаемой совокупности в пределах от 175,77 до 188,23 долл. составляет 95%.
Метод среднего:
Метод, использованный для создания доверительного интервала, можно модифицировать так, чтобы определить объем выборки с учетом желательного доверительного интервала. Предположим, что вы хотите рассчитать ежемесячный расход семьи на покупки в универмаге более точно -- так, чтобы полученный результат находился в пределах 5,0 долл. от истинного среднего значения исследуемой совокупности. Каким должен быть объем выборки? В таблице приведен необходимый перечень действий, которые вы должны выполнить.

- 1. Определите степень точности. Это максимально допустимое различие (D) между выборочным средним и генеральным средним. В нашем примере D = +5,0 долл.
- 2. Укажите уровень достоверности. Предположим, желательный уровень достоверности 95%.
- 3. Определите значение нормированного отклонения z, связанное с данным уровнем достоверности. При 95%-ном уровне достоверности вероятность того, что среднее значение генеральной совокупности выйдет за пределы одностороннего интервала, равна 0,025 (0,05/2). Соответствующее значение z составляет 1,96.
- 4. Определите стандартное отклонение среднего генеральной совокупности. Его можно получить из вторичных источников или рассчитать, проведя пилотное исследование. Кроме того, стандартное отклонение можно установить на основе мнения исследователя. Например, диапазон нормально распределенной переменной примерно укладывается в шесть стандартных отклонений (по три слева и справа от среднего значения).
5. Определите объем выборки, воспользовавшись формулой стандартной ошибки среднего
В нашем примере

(округленное в большую сторону до ближайшего целого числа).
Из формулы объема выборки видно, что он растет с ростом изменчивости (дисперсии) генеральной совокупности, а также с увеличением уровня достоверности и степени точности, с которой должны проводиться расчеты. Объем выборки прямо пропорционален Q2, поэтому, чем больше показатель дисперсии генеральной совокупности, тем больше объем выборки. Аналогично, более высокий уровень достоверности предполагает большее значение z и, следовательно, больший объем выборки. Переменные Q2 и z находятся в числителе. Увеличение степени точности достигается уменьшением значения D и, следовательно, увеличивает объем выборки, поскольку D находится в знаменателе.
6. Если объем выборки составляет 10% и больше от объема генеральной совокупности, то применяется окончательная коррекция совокупности (fpc). Затем необходимый объем выборки рассчитывается по формуле
7. Если среднеквадратичное отклонение совокупности о неизвестно и используется его предположительное значение, то его следует повторно рассчитать после получения выборки. Среднеквадратичное отклонение выборки s используется в качестве предположительного значения Q. Затем следует вычислить исправленный доверительный интервал, чтобы определить фактически полученную степень точности.
Предположим, что значение 55,00 использовалось в качестве предположительного значения а, потому что истинное значение было неизвестно. Получена выборка, в которой n = 465. На основе данных исследования рассчитывается среднее X, равное 180,00, и среднеквадратичное отклонение выборки s, равное 50,00. Тогда исправленный доверительный интервал составит:
Обратите внимание, что полученный доверительный интервал уже предполагаемого. Это вызвано тем, что среднеквадратичное отклонение совокупности завышено на основании выборочных характеристик.
8. Иногда точность определена в относительных, а не в абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от среднего. В этом случае объем выборки можно определить как
Объем генеральной совокупности N не влияет на объем выборки напрямую, за исключением случаев, когда применяется коэффициент окончательной коррекции совокупности. Возможно, это кажется невероятным, но если подумать, в этом утверждении есть смысл. Например, если исследуемые характеристики всех элементов совокупности идентичны, то выборки, состоящей из одного элемента, вполне достаточно, чтобы рассчитать среднее. Это также правильно, если совокупность состоит из 50, 500, 5000 или 50 000 элементов. В то же время изменчивость характеристик совокупности напрямую влияет на объем выборки. Эта изменчивость учитывается при вычислении объема выборки с помощью генеральной дисперсии Q2 или выборочной дисперсии s2.
Метод доли:
Если изучаемая статистика представлена не средним, а долей, то маркетолог определяет объем выборки аналогичным образом. Предположим, что исследователя интересует установление доли семей, владеющих кредитной карточкой универмага. Порядок действий будет следующим.
1. Укажите степень точности. Предположим, желательная степень точности такова, что допустимый интервал установлен на уровне
D = р -- л = ±0,05.
- 2. Укажите уровень достоверности. Предположим, что желателен 95%-ный уровень достоверности.
- 3. Определите значение z, связанное с данным уровнем достоверности. Как объяснялось при расчете среднего, оно составит 1,96.
- 4. Определите генеральную долю п. Как мы указывали раньше, ее можно получить из вторичных источников, в ходе экспериментального исследования или на основе мнения исследователя. Предположим, что на основе вторичных данных исследователь делает предположение, что 64% семей из изучаемой генеральной совокупности обладают кредитной карточкой универмага. Следовательно, л = 0,64.
- 5. Определите объем выборки с помощью формулы стандартной ошибки доли:
В нашем примере
- (округленное в большую сторону до целого числа).
- 6. Если конечный объем выборки составляет 10% и больше от объема совокупности, применяется окончательная коррекция совокупности (fpc). Затем необходимый объем выборки рассчитывается по формуле
где n -- объем выборки до применения окончательной коррекции; nс -- объем выборки после применения окончательной коррекции.
7. Если расчет тс был неверным, то доверительный интервал будет более или менее точным по сравнению с необходимым. Предположим, что по окончании выборки рассчитывается значение доли p, равное 0,55. Затем повторно вычисляется доверительный интервал, при этом sp используется для расчета неизвестного Qp , а именно:
В нашем примере
Доверительный интервал тогда равен 0,55 ± 1,96 (0,0264) = 0,55 + 0,052, что означает, что он шире, чем было задано. Это объясняется тем, что среднеквадратичное отклонение выборки p = 0,55 оказалось большим, чем предположительное значение среднеквадратичного отклонения генеральной совокупности при л = 0,64.
Если интервал, превышающий указанный, недопустим, объем выборки можно скорректировать так, чтобы отразить максимально возможное отклонение в генеральной совокупности. Такое отклонение происходит, когда произведение л (1 -- л) достигает максимального значения, для чего л должно равняться 0,5. К этому выводу можно прийти и без расчетов. Поскольку у одной половины совокупности одно значение характеристики, а у другой -- другое, потребуется больше данных, чтобы сделать правильный вывод, нежели когда ситуация более четко определена и у большинства элементов одно значение характеристики. В нашем примере это приведет к получению объема выборки, равного
- (округлено в большую сторону до целого числа).
- 8. Иногда точность определена в относительных, а не в абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от доли совокупности. Это означает, что D =Rл. В этом случае объем выборки можно определить как
Населения нередко проводятся среди больших групп людей. Зачастую ошибочным является представление о том, что достоверность результатов будет выше, если на вопросы ответит каждый член общества. Вследствие огромных временных, денежных затрат и трудоемкости такое обследование оказывается неприемлемым. С ростом численности респондентов не только увеличатся расходы, но и возрастет риск получения неверных данных. С практической точки зрения множество анкетеров и кодировщиков снизят вероятность достоверного контроля их действий. Такой опрос называется сплошным.
В социологии чаще всего применяется несплошное исследование, или выборочный метод. Результаты его могут распространяться на большую совокупность людей, которая именуется генеральной.
Определение и значение выборочного метода
Выборочный метод- это количественный способ отбора части исследуемых единиц из общей массы, при этом итоги обследования будут распространяться и на каждого индивида, не принявшего участия в этом.
Выборочный метод является и предметом научного исследования, и учебной дисциплиной. Он выступает средством получения достоверной информации о генеральной совокупности и помогает дать оценку всех ее параметров. Условия отбора единиц влияют в последующем на статистический анализ результатов. Если выборочные процедуры осуществлены некачественно, использование даже самых надежных методов обработки собранной информации окажется бесполезным.

Ключевые понятия теории выбора
Называют взаимосвязь единиц, относительно которых формулируются выводы выборочного исследования. В качестве нее могут выступать жители одной страны, конкретного населенного пункта, рабочий коллектив предприятия и т. д.
Выборочную совокупность (или выборку) составляет часть генеральной, которая была выделена с использованием специальных методик и критериев. Например, в процессе формирования учитываются статистические критерии.
Количество индивидов, вошедших в ту или иную совокупность, называют ее объемом. Но он может быть выражен не только числом людей, но и избирательными участками, населенными пунктами, то есть определенно крупными единицами, включающими в себя единицы наблюдения. Но это уже является многоступенчатой выборкой.
Единицей отбора являются составные части генеральной совокупности, ими могут быть как непосредственно единицы наблюдения (одноступенчатая выборка), так и более крупные формирования.
Большую роль в получении достоверных результатов исследования с применением выборочного метода является такое свойство, как репрезентативность отбора. То есть часть генеральной совокупности, ставшая респондентами, должна полностью воспроизводить все ее характеристики. Любое отклонение признается ошибкой.

Этапы применения выборочного метода
Каждое эмпирическое состоит из этапов. В случае применения выборочного метода их очередность будет выстроена следующим образом:
- Создание проекта выборки: устанавливается генеральная совокупность, характеризуются процедуры выбора, объемы.
- Реализация проекта: в ходе сбора социологической информации происходит выполнение анкетерами заданий с указанием способом отбора респондентов.
- Выявление и корректировка ошибок репрезентативности.
Типы выборок в социологии
После определения генеральной совокупности исследователь переходит к выборочным процедурам. Они могут разделяться по двум видам (критериям):
- Роль вероятностных законов в ходе осуществления выборки.
- Количество ступеней отбора.
Если применять первый критерий, то выделяют метод случайной выборки и неслучайный отбор. На основании последнего можно утверждать, что выборка может быть одноступенчатой и многоступенчатой.
Типы выборокпрямым образом отражаются не только на этапах подготовки и проведения исследования, но и на его результатах. Прежде чем отдать предпочтение одному из них, следует разобраться в содержании понятий.
Определение «случайный» в бытовом применении получило совершенно противоположенное значение, чем в математике. Такой отбор осуществляется по строгим правилам, не допускается никакое отступление от них, так как важно обеспечить каждой единице генеральной совокупности одинаковые шансы быть включенной в выборку. При несоблюдении данных условий эта вероятность будет разной.
В свою очередь случайная выборка подразделяется на:
- простую;
- механическую (систематическую);
- гнездовую (серийную, кластерную);
- стратифицированную (типическую или районированную).
Простой выборочный метод осуществляется при помощи таблицыслучайных чисел. Первоначально определяется объем выборки; создается полный перечень пронумерованных респондентов, входящих в генеральную совокупность. Используются для отбора специальные таблицы, содержащиеся в математико-статистических изданиях. Любые отличные от них применять запрещается. Если объем выборкипредставляет трехзначное число, то номер каждой единицы отбора должен быть трехзначным, а именно: от 001 до 790. Последнее число означает общее количество человек. В исследовании примут участие те люди, которым был присвоен номер в указанном диапазоне, встречающийся в таблице.

Систематический отбор основан на вычислениях. Предварительно составляется алфавитный список всех элементов генеральной совокупности, устанавливается шаг и только потом - объем выборки. Формула для шагапредставлена следующим образом:
N: n, где N - генеральная совокупность, а n - выборка.
Например, 150 000: 5 000 = 30. Таким образом, каждый тридцатый человек будет отобран для участия в опросе.
Сущность гнездового типа
Гнездовая выборка используется в условиях, если исследуемая совокупность людей состоит из маленьких по числу естественных групп. В таком случае следует учесть, что на первом шаге определяется списочное количество таких гнезд. При помощи таблицы случайных чисел происходит отбор и проводится сплошной опрос всех респондентов, состоящих в каждом отобранном гнезде. При этом чем больше их приняло участие в исследовании, чем меньше средняя ошибка выборки. Однако использовать такую методику возможно при условии наличия схожего признака у изучаемых гнезд.
Сущность стратифицированного выбора
Стратифицированная выборка отличается от предыдущих тем, что накануне отбора генеральная совокупность разбивается на страты, то есть однородные части, имеющие общий признак. Например, уровень образования, электоральные предпочтения, уровень удовлетворенности различными сторонами жизни. Самым простым вариантом является разделение испытуемых по полу и возрасту. Принципиально необходимо провести отбор таким образом, чтобы из каждой страты было выделено число лиц, пропорциональное общему количеству.
Объем выборки в таком случае может быть меньшим, чем в ситуации со случайным отбором, но при этом репрезентативность будет выше. Следует признать, что стратифицированная выборка будет самой затратной в финансовом и информационном плане, а гнездовая - самой выгодной в этом плане.

Неслучайная квотная выборка
Существует также квотная выборка. Она - единственный вид неслучайного отбора, который имеет математическое обоснование. Квотная выборка формируется из единиц, которые должны быть представлены пропорциями и соответствовать генеральной совокупности. В таким виде осуществляется целенаправленное распределение признаков. Если в числе исследуемых признаков выступают мнения, оценки людей, то квотными являются зачастую пол, возраст, образование респондентов.
В социологическом исследовании выделяют также два способа отбора: повторный и бесповторный. При первом избранная единица после обследования возвращается в генеральную совокупность, чтобы дальше участвовать в отборе. Во втором варианте респонденты отсортировываются, что повышает шансы остальных членов генеральной совокупности быть выбранным.
Ученый-социолог Г. А. Черчилль разработал такое правило: размер выборки должен стремиться обеспечить не меньше 100 наблюдений для первостепенных и 20-50 для второстепенной классификационной составляющей. Следует иметь в виду, что часть респондентов, вошедших в выборку, по различным причинам может не принять участие в опросе или вовсе от него отказаться.

Способы определения объема выборки
В социологических исследованиях применимы такие методы:
1. Произвольный, то есть объем выборки определяется в пределах 5-10 % состава генеральной совокупности.
2. Традиционный метод расчета основывается на проведении регулярных исследований, например, один раз в год с охватом 600, 2 000 или 2 500 респондентов.
3. Статистический - заключается в установлении надежности информации. Статистика как наука не развивается изолированно. Предметы и области ее исследования активно задействуются в других смежных отраслях: технических, экономических и гуманитарных. Так, ее методы используются в социологии, при подготовке к опросам и, в частности, при определении объемов выборок. Статистика как наука обладает обширной методологической базой.
4. Затратный, при котором установлена допустимая сумма расходов на исследование.
5. Объем выборки равен может быть числу единиц генеральной совокупности, тогда исследование будет носить сплошной характер. Такой подход применим в малых группах. Например, трудовой коллектив, студенты и т. д.
Ранее удалось установить, что выборка будет считаться репрезентативной, когда ее характеристики описывают свойства генеральной совокупности с минимальной погрешностью.
Оценка объема выборки предваряет окончательные расчеты количества единиц, которые будут выделены из генеральной совокупности:
n = Npqt 2: N∆ 2 p + pqt 2 , в которой N - количество единиц генеральной совокупности, p - доля изучаемого признака (q = 1 - p), t - коэффициент соответствия доверительной вероятности Р (определяется по специальной таблице), ∆ p - допустимая ошибка.
Это только один вариант того, как вычисляется объем выборки. Формула может изменяться в зависимости от условий и выбранных критериев исследования (например, повторная или бесповторная выборка).
Ошибки выборки
Социологические опросы населения основываются на использовании одного из типов выборки, рассмотренных нами выше. Однако в любом случае задачей каждого исследователя должна стать оценка степени точности полученных показателей, то есть нужно определить, насколько они отражают характеристики генеральной совокупности.
Ошибки выборки можно разделить на случайные и неслучайные. Первый вид подразумевает отклонение выборочного показателя от генерального, которое можно выразить разностью их долей (средней) и которое вызвано только не сплошным типом обследования. И совершенно закономерно, если этот показатель снижается на фоне увеличения количества опрошенных респондентов.
Систематической ошибкой называют отклонение от генерального показателя, также найденное в результате вычитания выборочной и генеральной доли и возникшее из-за несоответствия методики формирования выборки установленным правилам.
Данные типы ошибок входят в общую ошибку выборки. В исследовании из генеральной совокупности можно извлечь только одну выборку. Расчет величины максимально возможного отклонения выборочного показателя можно выполнить по специальной формуле. Оно называется предельной ошибкой выборки. Существует также такое понятие, как средняя ошибка выборки. Это среднее квадратическое отклонение выборочных от генеральной долей.
Выделяют также апостериорный (послеопытный) вид ошибки. Под ним подразумевается отклонение показателей выборочной от генеральной доли (средней). Оно вычисляется методом сравнения генерального показателя, информация о котором поступила от надежных источников, и выборочного, который был установлен в ходе опроса. В качестве достоверных источников информации выступают нередко отделы кадров предприятий, государственные органы статистики.
Существует также априорная ошибка, также являющаяся отклонением выборочного и генерального показателей, которой можно выразить разностью их долей и рассчитать которую можно по специальной формуле.

В учебных исследованиях чаще всего совершаются следующие ошибки, связанные с проведением отбора респондентов для опроса:
1. Выборочные совокупности групп, принадлежащие к разным генеральным. При их использовании разрабатываются статистические выводы, которые относятся ко всей выборке. Совершенно очевидно, что это не может быть приемлемо.
2. В расчет не принимаются организационные и финансовые возможности исследователя, когда рассматриваются типы выборок, и одной из них отдается предпочтение.
3. Не в полном объеме используются статистические критерии структуры генеральной совокупности при предотвращении ошибок выборки.
4. Не учитываются требования репрезентативности отбора респондентов в ходе сравнительных исследований.
5. Инструкция для интервьюера должна быть адаптирована с учетом специфики принятого типа отбора.
Характер участия респондентов в исследовании может быть открытым или анонимным. Это следует учитывать про формировании выборки, так как, не согласившись с условиями, участники могут выбыть.
В каждой профессии есть свой набор любимых вопросов. Для исследователей рынка этот список возглавляет, безусловно, вопрос о размере выборки. Обычно его формулируют так:
- Мы хотели бы заказать исследование по посетителям московских торговых центров. Какая нам нужна выборка?
- Наша целевая аудитория – примерно 300 000 человек. Сколько людей нам нужно опросить, чтобы было репрезентативно? А если целевая аудитория будет 3 млн?
- Нам нужно оценить потенциал продаж квартир в Санкт-Петербурге жителям северных городов России. Какую сделать выборку?
Главное заблуждение о размере выборки
Многие уверены, что чем больше размер целевой группы, тем больше должен быть размер выборки. Поэтому, якобы, чтобы узнать мнение жителей маленького города, достаточно опросить человек 200-300, ну а для выяснения мнения по России в целом и 5000 будет мало.
Между тем, этот стереотип не имеет ничего общего с реальностью. Размер выборки не зависит от численности целевой группы (на языке статистики она называется «генеральной совокупностью») и определяется двумя совершенно другими факторами. Единственное исключение из этого правила – случаи, когда генеральная совокупность очень маленькая, например, 1-2 тысячи человек, но такие ситуации в реальной практике маркетинговых исследований встречаются редко.
Два фактора, от которых зависит размер выборки
Размер выборки массового опроса зависит от двух факторов:
- Точности данных, которые нужно получить на выходе – это та самая «статистическая погрешность». Для выборки в 100 респондентов она будет в пределах плюс-минус 10%, а для выборки в 1000 респондентов – в пределах плюс-минус 3,1%. Более подробно об этом – ниже.
- Количества и размера подгрупп, на которые нужно разбивать выборку при анализе. Например, если проводится электоральное исследование, то в основном нас будет интересовать ядро активных избирателей. Как правило, доля «ядра» редко превышает 20-25% от всего населения. Поэтому размер выборки нужно рассчитывать так, чтобы одна четверть от ее общего объема позволяла проводить полноценный статистический анализ.
Две разновидности ошибки выборки
Любое выборочное наблюдение (то есть когда мы опрашиваем не всех подряд, а делаем случайный отбор из генеральной совокупности) сопряжено с погрешностью данных. Эту погрешность обычно называют «ошибкой выборки». Она может быть двух видов:
- Систематическая – связана с ошибками проектирования выборки. Оценить ее размер, направление и степень смещения очень сложно, чаще всего – невозможно. Например, если вопросы респондентам будут задавать представители маргинальных социальных слоев, это повлияет на готовность участвовать в исследовании со стороны представителей более обеспеченных групп населения. В итоге это приведет к крайне трудно оцениваемой систематической ошибке и искажению данных.
- Случайная – связана с действием законов статистики. Ее размер легко рассчитывается по формулам математической статистики и теории вероятности. Они позволяют делать обоснованные выводы о доверительном интервале признака. Например, если статистическая погрешность составляет плюс-минус 10%, а полученное значение показателя оказалось равно 25%, то доверительный интервал равен от 15% до 35%.

Задача исследователя – собрать данные так, чтобы минимизировать систематическую ошибку выборки. Тогда можно будет свести статпогрешность лишь к случайной ошибке, которую можно рассчитать по формулам.
Как рассчитать размер случайной ошибки выборки
Случайная ошибка выборки зависит не только от объема выборки, но и от дисперсии, то есть степени однородности данных. Чем однороднее данные (т.е. чем меньше разброс полученных значений, или дисперсия), тем меньше ошибка выборки.
Существует формула расчета случайной ошибки выборки, однако для удобства рекомендуем пользоваться онлайн-калькуляторами, например, вот этим . Он позволяет легко провести два вида расчета:
- рассчитать величину статистической погрешности на основе размера выборки и предполагаемой дисперсии;
- определить размер выборки, требуемый для получения оценки нужной степени точности.

В качестве параметра доверительной надежности (одно из полей в калькуляторе) обычно используется значение в 95%. Это означает, что в 95% случаев распределение признака в генеральной совокупности попадет в рассчитанный доверительный интервал (т.е. само значение признака в выборке плюс-минус размер статистической погрешности). Реже используется значение надежности в 97% или 99% – оно, соответственно, означает, что подобное попадание произойдет в 97% или 99% случаев. В данном случае надежность выборки повышается, но увеличивается размер выборки.
Самое сложное при определении размера выборки – поиск компромисса между требуемой точностью и стоимостью сбора данных. Этот процесс усложняется тем, что увеличение размера выборки в четыре раза приводит к увеличению точности лишь в два раза (соответствует квадратному корню от величины прироста выборки).
Кейс: определение размера выборки для оценки потенциала рынка продаж столичной недвижимости покупателям из регионов
В ноябре-декабре 2016 года мы провели исследование спроса на квартиры в новостройках Москвы и Санкт-Петербурга со стороны жителей разных городов России. Исследование включало в себя три метода сбора данных: массовый репрезентативный опрос населения в возрасте от 20 до 60 лет (проводился с использованием технологии CATI), а также серию экспертных интервью с риэлторами и глубинных интервью с потенциальными покупателями квартир.
Исследование охватывало 33 города, отличающихся повышенным спросом на петербургскую и московскую недвижимость. Плановая выборка исследования, рассчитанная по формулам, составила 21 500 респондентов. Этот объем значительно больше «стандартного» объема выборки, используемого в маркетинговых исследованиях. С чем же связан такой большой размер выборки?
Все дело в том, что клиенту были нужны оценки отдельно по каждому городу, а не просто «в целом по стране». Фактически мы работаем не с 1 выборкой, а с 33 отдельными выборками по каждому городу. Доля людей, заинтересованных в покупке квартиры в Санкт-Петербурге или Москве, была экспертно определена в рамках 5% от числа жителей опрашиваемых городов.
В зависимости от важности города для заказчика, руководитель проекта со стороны Агентства определил допустимую статистическую погрешность, в которую должны укладываться итоговые результаты. Для этого мы использовали специальный макрос в MS Excel, но эти расчеты можно также выполнить с помощью калькулятора выборки. В результате размер выборки варьировал от 500 до 1000 респондентов по каждому из городов исследования, что в сумме и дало заявленные 21 500 человек.
- Определите структуру целевой группы. Планируете ли вы анализировать отдельные подгруппы или достаточно будет анализа по выборке в целом?
- Определите желаемую точность данных. Например, если нужно оценить динамику рыночной доли за год, подставьте в специальный калькулятор примерное значение доли и «поиграйте» с разными объемами выборки.
- Найдите баланс между стоимостью сбора данных (прямо пропорциональна объему выборки) и требуемой точностью.
Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:
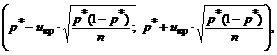
где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |  |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193
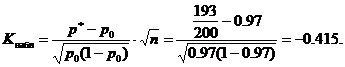
Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например, «Да» и «Нет»; «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборки при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный - доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p - это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96 . Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они - «Да». Тогда p = 0,5 . Отсюда находим q = 1 – p = 1 – 0,5 = 0,5 . Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1 .
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек .
Область применения данной формулы
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» - «Нет», «Черное» - «Белое», и т.д.
Особенности данной формулы расчета объема выборки
Галяутдинов Р.Р.
© Копирование материала допустимо только при указании прямой гиперссылки на





