Матрица расстояний в графе и ее нахождение. Графы дорожных сетей и алгоритмы работы с ними. Раскраска графа, хроматический полином
Выберите в меню Сервис пункт Анализ данных , появится окно с одноименным названием, главным элементом которого является область Инструменты анализа . В данной области представлен список реализованных в Microsoft Excel методов статистической обработки данных. Каждый из перечисленных методов реализован в виде отдельного режима работы, для активизации которого необходимо выделить соответствующий метод указателем мыши и щелкнуть по кнопке ОК. После появления диалогового окна вызванного режима можно приступать к работе.
Режим работы «Скользящее среднее » служит для сглаживания уровней эмпирического динамического ряда на основе метода простой скользящей средней.
Режим работы «Экспоненциальное сглаживание » служит для сглаживания уровней эмпирического динамического ряда на основе метода простого экспоненциального сглаживания.
В диалоговых окнах данных режимов (рисунок 2 и 3) задаются следующие параметры:
2. Флажок Метки – устанавливается активное состояние, если первая строка (столбец) во входном диапазоне содержит заголовки. Если заголовки отсутствуют, флажок следует деактивизировать. В этом случае будут автоматически созданы стандартные названия для данных выходного диапазона.
3. Интервал (только в диалоговом окне Скользящее среднее) – вводится размер окна сглаживания р . По умолчанию р=3 .
Рисунок 2 – Диалоговое окно скользящего среднего
4. Фактор затухания (только в диалоговом окне Экспоненциальное сглаживание) – вводится значение коэффициента экспоненциального сглаживания p . По умолчанию, p=0,3 .
5. Выходной интервал / Новый рабочий лист / Новая рабочая книга – в положении Выходной интервал активизируется поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного диапазона. Размер выходного диапазона будет определен автоматически, и на экране появится сообщение в случае возможного наложения выходного диапазона на исходные данные. В положении Новый рабочий лист открывается новый лист, в который начиная с ячейки А1 вставляются результаты анализа. Если необходимо задать имя в поле, расположенное напротив соответствующего положения переключателя. В положении Новая рабочая книга открывается новая книга, на первом листе которой начиная с ячейки А1 вставляются результаты анализа.
6. Вывод графика – устанавливается в активное состояние для автоматической генерации на рабочем листе графиков фактических и теоретических уровней динамического ряда.
7. Стандартные погрешности – устанавливаются в активное состояние, если требуется включить в выходной диапазон столбец, содержащий стандартные погрешности.

Рисунок 3 – Диалоговое окно экспоненциального сглаживания
Пример 1.
Данные о реализации (млн. руб.) продуктов сельскохозяйственного производства магазинами потребительской кооперации города приведены в таблице, сформированной на рабочем листе Microsoft Excel (рисунок 4). В указанном периоде (2009 – 2012 гг.) требуется выявить основную тенденцию развития данного экономического процесса.

Рисунок 4 – Исходные данные
Для решения задачи используем режим работы «Скользящее среднее ». Значения параметров, установленных в одноименном диалоговом окне, представлены на рисунке 5, рассчитанные в данном режиме показатели – на рисунке 6, а построенные графики – на рисунке 7.

Рисунок 5 – Заполнение диалогового окна

Рисунок 6 – Результаты анализа

Рисунок 7– Скользящее среднее
В столбце D (рисунок 5) вычисляются значения сглаженных уровней. Например, значение первого сглаженного уровня рассчитывается в ячейке D5 по формуле =СРЗНАЧ(С2:С5), значение второго сглаженного уровня – в ячейке D6 по формуле =СРЗНАЧ(С5:С8) и т.д.
В столбце E вычисляются значения стандартных погрешностей с помощью формулы =КОРЕНЬ (СУММАКВРАЗН (блок фактических значений; блок прогнозных значений) / размер окна сглаживания).
Например, значение в ячейке Е10 рассчитывается по формуле =КОРЕНЬ(СУММКВРАЗН(С7:С10;О7:В10)/4).
Вместе с тем, как отмечалось выше, если размер окна сглаживания является четным числом (р=2m ), то рассчитанное усредненное значение нельзя сопоставить какому-либо определенному моменту времени t, поэтому необходимо применять процедуру центрирования.
Для рассматриваемого примера р=4 , поэтому процедура центрирования необходима. Так, первый сглаженный уровень (265,25) записывается между II и III кв. 2009 г. и т.д. Применяя процедуру центрирования (для этого используем функцию СРЗНАЧ), получаем сглаженные уровни с центрированием. Для III кВ. 2009 г. определяется серединное значение между первым и вторым сглаженными уровнями: (265,25 + 283,25)/2 = 274,25; для IV кв. 2009 г. центрируются второй и третий сглаженные уровни: (283,25 + 292,00)/2 = 287,6 и т.д. Рассчитанные значения представлены в таблице 1. Скорректированный график скользящей средней представлен на рисунке 8.
Таблица 1 – Динамика сглаженных уровней реализации продукции
| Год | Квартал | Размер реализации, млн. руб. | Сглаженные уровни с центрированием |
| 274,25 | |||
| 287,63 | |||
| 297,00 | |||
| 307,50 | |||
| 334,63 | |||
| 374,13 | |||
| 402,88 | |||
| 421,00 | |||
| 429,00 | |||
| 430,75 | |||
| 435,38 | |||
| 446,63 | |||

Рисунок 8 – Скорректированный график скользящего среднего
Пример 2.
Рассмотренная задача может быть решена и с помощью метода простого экспоненциального сглаживания. Для этого необходимо использовать режим работы «Экспоненциальное сглаживание». Значения параметров, установленных в одноименном диалоговом окне, представлены на рисунке 9, рассчитанные в данном режиме показатели – рисунок 10, а построенные графики – на рисунке 11.

Рисунок 9 – Заполнение диалогового окна «Экспоненциальное сглаживание»

Рисунок 10 – Результаты анализа

Рисунок 11 – Экспоненциальное сглаживание
В столбце D (рисунок 10) вычисляются значения сглаженных уровней на основе рекуррентных соотношений.
В столбце E рассчитываются значения стандартных погрешностей с помощью формулы =КОРЕНЬ(СУММКВРАЗН (блок фактических значений; блок прогнозных значений) / 3). Как легко заметить (сравните рисунок 8 и 11), при использовании метода простого экспоненциального сглаживания, в отличие от метода простой скользящей средней, сохраняются мелкие волны.
Скользящее среднее или просто МА (Moving Average) , является среднеарифметическим ценового ряда. Общая формула скользящего среднего следующая:
Где:
МА – скользящее среднее;
n- период усреднения;
Х – значения цены акции.
Для прогнозирования цены акции на несколько периодов вперед воспользуемся формулой. Прогноз цены в следующем период будет равнять значения скользящего среднему в предыдущем периоде.
![]()
Спрогнозируем
с помощью модели скользящего среднего стоимость акций
компании Аэрофлот (AFLT)
. Для этого экспортируем котировки акции с сайта finam.ru за половину 2009 года. Всего будет 20 значений.

График стоимости акций Аэрофлота за выбранный промежуток времени представлен ниже.

Выбор периода усреднения
n
в модели скользящего среднего
Использование большего в модели МА(n) приводит к сильному искажению данных, в результате чего существенные значения ценового ряда усредняются, и в результате теряется четкость прогноза, можно сказать что он становится “размытым”. Использование слишком мелкого периода усреднения добавляет в прогноз больше шумовой компоненты. Как правило, период усреднения подбирается эмпирическим путем на исторических данных.
Построим скользящее среднее с периодом усреднения в три месяца MA(3). Для расчета значения скользящего среднего для акции, воспользуемся формулой Excel.
СРЗНАЧ(C2:C4)
В колонке “D” рассчитаны значения скользящего среднего с периодом усреднения 3.

После расчета скользящего среднего построим прогноз на 3 периода вперед (на три месяца вперед). Воспользуемся формулой для определения значения цены акции, первое прогнозное значение будет равно последнему значению скользящего среднего. Оранжевая область это область прогнозов. С22 будет равна значению скользящего среднего, то есть:
С22 =D21 С23=D22 и т.д.
От новых прогнозных данных стоимости акции рассчитывается скользящее следующее среднее.
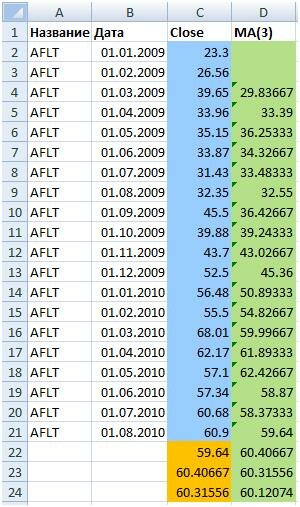
Построим прогнозные значения по скользящему среднему для акций Аэрофлота на три месяца вперед. Ниже представлен график и прогнозные значения акции.
В математике сети дорог (автомобильных и не только) представляются взвешенным графом. Населенные пункты (или перекрестки) - это вершины графа, ребра - дороги, веса ребер - расстояния по этим дорогам.
Для взвешенных графов предлагается множество алгоритмов. Например, популярный алгоритм Дейкстры для поиска кратчайшего пути от одной вершины до другой. У всех этих алгоритмов есть общая принципиальная (для математики) особенность - они универсальны, т.е. могут успешно применяться для графов любой конструкции. В частности, для каждого алгоритма известна его сложность – она примерно соответствует увеличению времени выполнения алгоритма в зависимости от числа вершин графа. Все это подробно можно прочитать, например, в википедии.
Вернемся к практическим задачам. Дороги представляются взвешенным графом, но дороги - это не любой граф. Другими словами, нельзя из любого графа построить дорожную сеть. В отличие от виртуального графа как математической абстракции, дороги строятся людьми из реальных материалов и стоят довольно больших денег. Поэтому они прокладываются не как попало, а по определенным экономическим и практическим правилам.
Мы не знаем эти правила, однако, работая с дорожными сетями, вполне можно использовать алгоритмы, которые эффективны для графов дорог, хотя и не подходят для графов в универсальном или математическом смысле. Рассмотрим здесь два таких алгоритма.
Несколько важных понятий и условностей
1. Мы будем использовать взвешенные неориентированные графы с неотрицательными весами ребер. В частности, дороги в рамках региона (страны) представляют собой именно такой граф.2. Матрица кратчайших расстояний (МКР) – ее маленький и простой пример можно найти во многих дорожных атласах. Эта табличка обычно называется примерно так: «расстояния между наиболее важными городами». Она выглядит как часть матрицы ниже или выше главной диагонали (из верхнего левого в нижний правый угол), потому что с другой стороны главной диагонали точно такие же цифры, другими словами элемент М(i,j)= М(j,i). Это происходит, потому что граф, как говорят математики, неориентированный. Строки и столбцы соответствуют городам (вершинам графа). В реальности такая таблица намного больше, так как в вершины графа, кроме городов, входят все деревни и перекрестки, но напечатать такую большую таблицу в атласе, естественно, невозможно.
Первым делом продолжим (мысленно) нашу таблицу на верхнюю часть, получим МКР, симметричную относительно главной диагонали и далее будем иметь в виду именно такую таблицу. В этом случае, столбец с некоторым номером равен строке с таким же номером и все равно, какое из понятий использовать. Мы используем и то, и другое, чтобы их пересекать между собой.
Наша МКР может быть: а) известна заранее, потому что мы ее подсчитали одним из методов поиска МКР; б) мы можем не знать МКР, а определять ее построчно по мере необходимости. Построчно – это значит, что для требуемой строки рассчитываются расстояния только от соответствующей ей вершины до остальных вершин, например, методом Дейкстры.
3. Еще пара понятий. Эксцентриситет данной вершины – это расстояние от этой вершины до самой удаленной от нее. Радиус графа – это наименьший из эксцентриситетов всех вершин. Центр графа – вершина, эксцентриситет которой равен радиусу.
Как это выглядит на практике. Центр дорожной сети – это город или перекресток, наименее удаленный от всех остальных пунктов этой сети. Радиус – максимальное расстояние от этого центрального узла до самого удаленного.
4. Степень вершины – количество ребер, которое присоединено к вершине.
У графов дорожных сетей, средняя степень всех вершин находится в районе от 2 до 4. Это вполне естественно – сложно и дорого строить перекрестки с большим количеством примыкающих дорог, не менее сложно потом пользоваться такой дорожной сетью. Графы, с невысокой средней степенью вершин называются разреженными, как видим, графы дорожных сетей именно такие.
Задача 1. Поиск радиус и центра графа по матрице кратчайших расстояний
Заметим, что у графа может быть несколько центров, но мы хотим найти любой из них.Как задача решается в общем случае? Полным просмотром МКР. Ищется максимальный элемент в строке (эксцентриситет каждой вершины), а потом из этих максимальных элементов находится минимальный.
Это далеко не самый быстрый способ. Для чего нужно быстрее, если, казалось бы, радиус и центр графа можно найти один раз? Например, существуют задачи и алгоритмы на них, где в ходе перебора вершины постоянно «переобъединяются» в группы, а критерием для каждой группы является ее радиус. В этом случае радиус пересчитывается многократно, и скорость его поиска становится важным параметром. Как найти радиус быстрее?
Секрет в том, что для графов дорожных сетей все элементы просматривать не обязательно. На практике, достаточно просмотреть весьма малую часть всех строк.
Посмотрим, за счет чего это получается. Рассмотрим значения в одной строке матрицы МКР, другими словами, рассмотрим расстояния от одной вершины до всех остальных. Несложно доказать, что радиус графа не может быть больше чем максимальное значение в этой строке, и не может быть меньше чем минимальное значение в этой строке. Говоря математически, мы нашли верхнюю и нижнюю границу числа и если они совпадут – мы найдем число.
Допустим, мы нашли значения всего лишь в двух строках А и В. При этом, максимальное значение в строке А равно минимальному значению в строке В (эта величина будет стоять на пересечении столбца А и строки В). Несложно доказать, что А – центр графа, а найденное значение – его радиус. Задача решена.
Здорово, но такая ситуация на графах дорожных сетей маловероятна и решать задачу таким образом не получится. Поступим хитрее.
Возьмем пару строк В1 и В2. Из них сформируем вектор М таким образом: М(i)=max. Несложно доказать, что если для всех строк i значение min(M(i)) равно максимальному значению в столбце А, то, опять таки, А – центр, а найденное min(M(i)) – радиус.
Если пары строк окажется недостаточно, можно взять несколько строк, например три: B1, B2 и B3, тогда М(i)=max. Особенность графов дорожных сетей состоит в том, что много строк не понадобится (удастся уложиться в десяток). Это легко проверить, поэкспериментировав на существующих графах сетей, скачав их из интернета: ссылка .
В общем случае и с точки зрения математики это, конечно, не так. Вполне можно построить теоретический граф в котором придется использовать очень много строк В (почти все, кроме, А). Вот только невозможно построить реальную дорожную сеть такого вида - денег не хватит.
Осталась последняя задача. Как быстро найти эти удачные строки B1, B2 и т.д. Для графов реальных дорожных сетей это сделать очень просто и быстро. Это будут максимально удаленные друг от друга вершины, но не обязательно самые удаленные (говоря математически, находить диаметр графа нам не требуется). Берем любую вершину, находим для нее самую дальнюю, для новой опять самую дальнюю и так, пока пара вершин не окажется самой дальней друг для друга.
Мы получили пару вершин В1 и В2. Находим для пары вектор М, как описано выше. Строка, в которой мы нашли min(M(i)) - претендент на центр, обозначим его А. Если в столбце А значение min(M(i)) – максимальное, то уже найдены центр и радиус. Если же нет, значит максимальное значение в столбце А соответствует расстоянию до другой вершины (не B1 и не B2). Значит, мы получили новую вершину B3 в список на поиск вектора М. Как вариант, можно и для B3 поискать самую удаленную вершину и если она не В1 и не B2, добавить ее как В4. Таким образом, увеличиваем список вершин B, пока центр и радиус не будут найдены.
Более строго, с алгоритмом и нужными доказательствами этот алгоритм описан в , там же приведены результаты его использования на некоторых графах дорожных сетей США, а в ссылка и ссылка он описан менее академически, но более понятно.
Задача 2. Поиск матрицы кратчайших расстояний
Наиболее популярные алгоритмы поиска МКР (Флойда-Уоршелла, например) описаны . Все они универсальные, причем один из них – алгоритм Дейкстры с двоичной кучей – учитывает такое понятие как разреженный граф. Однако он тоже не использует особенности дорожных сетей.Мы будем их использовать и на совершенно другом алгоритме и на существующих графах получим ускорение в десятки раз по сравнению с алгоритмом Дейкстры. Заметим сразу, что особенность этого алгоритма в том, что ищет именно МКР, причем сразу всю и точно (т.е. не приближенно, не эвристически).
Рассмотрим основную идею алгоритма. Суть ее в том, чтобы удалять вершины графа без изменения кратчайших расстояний для оставшихся точек. Если мы будем так делать, запоминая к каким точкам и на каких расстояниях была присоединена удаленная вершина, то сможем удалить все точки, кроме одной, а потом собрать их обратно в граф, но с уже подсчитанными расстояниями.
Начнем с простого, с вершины со степенью 1. Ее можно удалить в любом случае. Через нее не проходит никаких кратчайших путей, кроме путей к самой вершине, причем идут они именно через ту вершину, к которой была присоединена удаляемая вершина.
Пусть А – вершина со степенью 2 и присоединена она в вершинам В1 и В2. Если маршрут В1-А-В2 длиннее или равен ребру В1-В2, через точку А не проходит никаких маршрутов, кроме маршрутов к самой точке А (все остальные проходят через В1-В2). Значит, точку А можно удалить. В ином случае, т.е. если В1-А-В2 короче В1-В2 или ребра В1-В2 вообще нет, вершину А можно удалить, установив вес ребра В1-В2 равным сумме весов: |В1-А|+|А-В2|. Маршрут от А до других точек проходит либо через В1, либо через В2, если будут известны расстояния для В1 и В2, расстояния от А так же легко вычислить.
По такому же принципу можно удалить вершину с любой степенью, заменяя, по мере необходимости, Вi-А-Вj на Bi-Bj. Правда, нужно понимать, что чем больше степень вершины, тем больше возможных ребер надо проверить. Для вершины степени n это число равно n(n-1)/2.
Теоретически, таким способом можно удалить все вершины в любом графе, однако, в общем случае, нас ждет неприятность, связанная с ростом числа ребер. При удалении вершины со степенью n, степень вершин, смежной с удаляемой, может: уменьшится на -1, не измениться, увеличится до n-2. Отсюда следует, что при удалении вершин со степенью 3 и выше, степень остальных вершин, в общем случае, растет, граф становится все менее разреженным и, в конце концов, удаление вершин превратится в довольно трудоемкую задачу. Алгоритм, в общем случае, является крайне трудоемким и практически бесполезным, но это именно в общем случае.
Графы дорожных сетей имеют уникальную особенность такого рода: многие вершины могут быть удалены не только без роста, но и с уменьшением степени смежных вершин. Причем, если некоторая вершина не может быть «успешно» удалена сейчас, она может быть «успешно» удалена позже, после удаления некоторых, смежных с ней вершин.
Соответственно, нам просто требуется на каждом шаге правильно выбирать вершины на удаление, начиная с тех, которые удаляются более «удачно».
Сам алгоритм более подробно можно посмотреть
В прошлом параграфе мы подчеркнули, что введенная там матрица смежности $A$, точнее матрица вершинной смежности графа, играет весьма существенную роль в теории графов. Мы отметили в качестве преимуществ этой матрицы — она квадратная порядка, равного числу строк матрицы инцидентности $B$, т.е., как правило, содержит меньшее число элементов. Во-вторых, эта матрица сохраняет всю информацию о ребрах графа и, при заданной нумерации вершин, однозначно описывает граф. Матрица смежности, как и матрица инцидентности графа, является (0,1)-матрицей, т.е. её элементы можно рассматривать как элементы других алгебраических структур, а не только как элементы множества целых чисел. В частности мы отметили, что элементы матрицы смежности могут рассматриваться как элементы булевой алгебры, подчиненные законам булевой арифметики, но не пояснили это должным образом. Прежде чем восполнить этот пробел, подчеркнем преимущества матрицы смежности, вытекающие из её квадратности.
Для этого напомним правила умножения матриц. Пусть даны произвольные матрицы с числовыми элементами: матрица $A$ размерности $n\times m$ с элементами $a_{ik}$ и матрица $B$ размерности $m\times q$ с элементами $b_{kj}$. Матрица $C$ размерности $n\times q$ называется произведением матрицы $A$ на $B$ (порядок важен), если её элементы $c_{ij}$ определяются следующим образом: $c_{ij} = \sum\limits_{k = 1}^m {a_{ik} b_{kj}}$. Произведение матриц записывается обычным образом $AB=C$. Как видим, произведение матриц требует согласованности размеров первого и второго сомножителей (число столбцов первой матрицы-сомножителя равно числу строк второй матрицы-сомножителя). Это требование отпадает, если рассматривать квадратные матрицы одного порядка и, следовательно, можно рассматривать произвольные степени квадратной матрицы. Это одно из преимуществ квадратных матриц перед прямоугольными. Другое преимущество состоит в том, что мы можем дать графовую интерпретацию элементам степеней матрицы смежности.
Пусть матрица смежности $A$ имеет вид: $A = \left({{\begin{array}{*c} {a_{11} } & {a_{12} } & {...} & {a_{1n} } \\ {a_{21} } & {a_{22} } & {...} & {a_{2n} } \\ {...} & {...} & {...} & {...} \\ {a_{n1} } & {a_{n2} } & {...} & {a_{nn} } \\ \end{array} }} \right)$, а её $k$-ая степень — $A^k = \left({{\begin{array}{*c} {a_{11}^{(k)} } & {a_{12}^{(k)} } & {...} & {a_{1n}^{(k)} } \\ {a_{21}^{(k)} } & {a_{22}^{(k)} } & {...} & {a_{2n}^{(k)} } \\ {...} & {...} & {...} & {...} \\ {a_{n1}^{(k)} } & {a_{n2}^{(k)} } & {...} & {a_{nn}^{(k)} } \\ \end{array} }} \right)$, где $k = 2,3,...$ Очевидно, что $A^k$, как и матрица $A$ будет симметричной матрицей.
Пусть $k=2$. Тогда $a_{ij}^{(2)} = \sum\limits_{k = 1}^n {a_{il} a_{lj}}$ ($i,j = 1,2,...,n$), и каждое слагаемое $a_{il} a_{lj}$ равно либо $0$, либо $1$. Случай, когда $a_{il} a_{lj} = 1$ означает, что в графе существуют два ребра: ребро $\{i,l\}$ (поскольку $a_{il} = 1)$ и ребро $\{l,j\}$ (поскольку $a_{lj} = 1$) и, следовательно, путь $\{{ \{i,l\}, \{l,j\} }\}$ из $i$-ой вершины в $j$-ую длиной два (путь из двух ребер). Здесь речь идет именно о пути, а не цепи, поскольку указано направление — из из $i$-ой вершины в $j$-ую. Таким образом, $a_{ij}^{(2)}$ дает нам количество всех путей на графе (в геометрической интерпретации графа) длины 2, ведущих из $i$-ой вершины в $j$-ую.
Если $k=3$, то $A^3 = A^2A = AA^2 = AAA$ и $a_{ij}^{(3)} = \sum\limits_{l_1 = 1}^n {a_{il_1 } } a_{l_1 j}^{(2)} = $ $\sum\limits_{l_1 = 1}^n {a_{il_1 } } \left({\sum\limits_{l_2 = 1}^n {a_{l_1 l_2 } a_{l_2 j} } } \right) =$ $\sum\limits_{l_1 = 1}^n {\sum\limits_{l_2 = 1}^n {a_{il_1 } } } a_{l_1 l_2 } a_{l_2 j} = \sum\limits_{l_1 ,l_2 = 1}^n {a_{il_1 } a_{l_1 l_2 } a_{l_2 j} }$.
Слагаемое $a_{il_1 } a_{l_1 l_2 } a_{l_2 j} $ в случае если оно равно 1, определяет путь длины 3 идущий из $i$-ой вершины в $j$-ую и проходящий через вершины $l_1$ и $l_2$. Тогда $a_{ij}^{(3)}$ дает нам количество путей длины 3, соединяющих $i$-ую и $j$-ую вершины. В общем случае $a_{ij}^{(k)}$ задает количество путей длины $k$, соединяющих $i$-ую и $j$-ую вершины. При этом $a_{ij}^{(k)} = \sum\limits_{l_1 ,l_2 ,...,l_{k - 1} = 1}^n {a_{il_1 } a_{l_1 l_2 } ...} a_{l_{k - 2} l_{k - 1} } a_{l_{k - 1} j}$.
Ясно, что величина $a_{ii}^{(k)} $ дает нам количество замкнутых путей длины $k$, начинающихся и оканчивающихся в вершине $i$. Так, путь длины 2 — $a_{il} a_{li}$, означает путь, проходящий по ребру $\{ i,l \}$ из вершины $i$ в вершину $l$ и обратно. Поэтому $a_{ii}^{(2)} = s_i$, т.е. диагональные элементы матрицы $A^2$ равны степеням соответствующих вершин.
Рассмотрим теперь наряду с матрицей $A$ матрицу $\dot {A}$, которая отличается от матрицы $A$ только тем, что у неё элементы (числа 0 или 1) рассматриваются как элементы булевой алгебры. Поэтому действия с такими матрицами будут проводиться по правилам булевой алгебры. Поскольку действия сложения и умножения матриц с булевыми элементами сводится к действиям сложения и умножения элементов этих матриц по правилам булевой арифметики, то, надеемся, что это не приведет к затруднениям. Матрицу с булевыми элементами будем называть булевой матрицей. Очевидно, что операции сложения и умножения булевых матриц замкнуты на множестве булевых матриц, т.е. результат этих операций будет снова булевой матрицей.
Очевидно, что при заданной нумерации вершин между булевыми матрицами смежности и графами существует взаимно однозначное соответствие. Поэтому представляет интерес графовая интерпретация действий сложения и возведения в степень булевых матриц смежности (в общем случае произведение двух симметричных матриц одного порядка не обязательно симметричная матрица).
Результатом сложения двух булевых симметричных матриц одного порядка будет булева симметричная матрица того же порядка с нулями на тех местах, на которых у обоих слагаемых стоят нули и единицами на тех местах, на которых по крайней мере у одного слагаемого стоит единица. В графовой интерпретации эта операция называется операцией сложения графов . Суммой двух графов , заданных на одном и том же множестве вершин с одной и той же их нумерацией, называется граф, у которого вершины i и j несмежные, если они несмежные у обоих графов-слагаемых, и вершины i и j смежные, если они смежные хотя бы у одного графа-слагаемого .
Проинтерпретируем теперь вторую степень булевой матрицы смежности $\dot {A}^2$ с элементами $\dot {a}_{ij}^{(2)} = \sum\limits_{l = 1}^n {\dot {a}_{il} \dot {a}_{lj} }$. Ясно, что $\dot {a}_{ij}^{(2)} = 1$, если хотя бы одно слагаемое $\dot {a}_{il} \dot {a}_{lj} $ равно 1 и $\dot {a}_{ij}^{(2)} = 0$, если все слагаемые равны 0. Если матрица $\dot {A}$ является матрицей смежности некоторого графа, т.е. является симметричной (0,1)-матрицей с нулевой главной диагональю, то матрица $\dot {A}^2$, вообще говоря, не является матрицей смежности графа в принятом нами смысле, поскольку у неё все диагональные элементы равны 1 (если у графа нет изолированных вершин). Чтобы и на такие матрицы можно было смотреть как на матрицы смежности, мы должны при рассмотрении связей между вершинами некоторой связанной системы, определяющих эту систему как граф, допустить связь некоторых вершин самих с собой. «Ребро», определяющее связь некоторой вершины самой с собой называется петлей . Мы дальше, по-прежнему, под словом граф будем понимать граф без петель, а про граф с петлями, если это не будет ясно из контекста, так и будем говорить — граф с петлями.
Рассмотрим сумму $\dot {A}^{} = \dot {A} + \dot {A}^2$. Матрица $\dot {A}^{}$ задает нам граф, полученный из исходного «насыщением» его дополнительными связями, соответствующими путям длины 2. То есть в новом графе вершины $i$ и $j$ смежные, если они смежные в исходном графе или эти вершины связаны каким-нибудь путем длины 2, и вершины $i$ и $j$ несмежные, если они несмежные в исходном графе и не существует никакого пути длины 2, соединяющего эти вершины.
Аналогично определяется $\dot {A}^{} = \dot {A} + \dot {A}^2 + \dot {A}^3$. То есть в графе, заданном матрицей $\dot {A}^{}$ вершины $i$ и $j$ смежные, если они смежные в графе $\dot {A}^{}$ или эти вершины связаны каким-нибудь путем длины 3 в исходном графе, и вершины $i$ и $j$ несмежные, если они несмежные в графе $\dot {A}^{}$ и не существует никакого пути длины 3, связывающих эти вершины в исходном графе. И так далее.
В общем случае $\dot {A}^{[k]} = \sum\limits_{i = 1}^k {\dot {A}^i} $. Нетрудно видеть, что все $\dot {A}^{[k]}$ при $k \ge n - 1$, где $n$ — порядок матрицы $\dot {A}$, равны между собой. Действительно, если вершины $i$ и $j$ связны, то существует путь (цепь) связывающий эти вершины, а, следовательно, существует простой путь (простая цепь) связывающий эти вершины. Максимальная возможная простая цепь в $n$-вершинном графе имеет длину $n-1$ (простая цепь, связывающая все различные вершины графа). Поэтому, если в матрице $\dot {A}^{}$ на месте $(i,j)$ стоит 1, то на этом же месте в матрице $\dot {A}^{[k]}$ при $k \ge n - 1$ будет также стоять 1, поскольку матрица $\dot {A}^{}$ входит в качестве булева слагаемого в определение матрицы $\dot {A}^{[k]}$. Если же в матрице $\dot {A}^{}$ на месте $(i,j)$ стоит 0, то это значит, что в графе не существует никакой простой цепи, соединяющей $i$-ую и $j$-ую вершины, а, следовательно, не существует вообще никакой цепи связывающей эти вершины. Значит, в рассматриваемом случае и в матрице $\dot {A}^{[k]}$ при $k \ge n - 1$ на месте ($i$,$j)$ будет стоять 0. Что и доказывает наше утверждение о равенстве всех матриц $\dot {A}^{[k]}$ при $k \ge n - 1$ матрице $\dot {A}^{}$ и, следовательно, между собой.
Матрицу $\dot {A}^{}$ называют матрицей транзитивного замыкания матрицы $\dot {A}$, а также матрицей смежности транзитивного замыкания графа, заданного матрицей $\dot {A}$. Достаточно очевидно, что матрицей транзитивного замыкания связного графа будет матрица смежности полного графа, т.е. квадратная матрица, состоящая из одних единиц. Это наблюдение дает нам и метод определения связности графа: граф связный тогда и только тогда, когда матрица транзитивного замыкания его матрицы смежности будет состоять из одних единиц (будет матрицей полного графа) .
Матрица транзитивного замыкания позволяет также решать задачу разбиения графа на компоненты связности.
Покажем теперь, как процедура транзитивного замыкания позволяет построить так называемую «матрицу расстояний». Для этого определим расстояние между вершинами $i$ и $j$. Если вершины $i$ и $j$ связные, то расстоянием между ними назовем длину минимального (по числу обхода ребер) простого пути, связывающего эти вершины; если вершины $i$ и $j$ несвязные, то положим расстояние равным нулю (ноль как отрицание какого-либо пути связывающего эти вершины). При таком определении расстояния расстояние между вершиной и ею же самой равно 2 (длина пути по ребру и обратно). Если же при вершине имеется петля, то расстояние между вершиной и ею же самой равно 1.
Для построения матрицы расстояний для $n$-вершинного графа с матрицей смежности $A$, которая указывала бы расстояние между любыми двумя вершинами, введем в рассмотрение матрицы $A^{\{k\}} = A^{[k]} - A^{}$, где $k = 2,3,...,n - 1$ и $A^{\{1\}} = A^{} = A$. Отсутствие точек над обозначением матриц указывает, что мы рассматриваем матрицы $A^{[k]}$ ($k = 1,2,...,n - 1)$ как числовые (0,1)-матрицы, естественным образом получаемые из матриц $\dot {A}^{[k]}$ (булевы элементы 0 и 1 мы теперь рассматриваем как числа 0 и 1). Из способа построения матриц $A^{[k]}$ следует, что $A^{[k]} \ge A^{}$ ($k = 2,3,...,n - 1$) и, следовательно, $A^{\{k\}}$ ($k = 1,2,...,n - 1$) являются (0,1)-матрицами. Причем матрица $A^{\{2\}}$ содержит 1 только на тех местах, где определяемые этим местом (номер строки и номер столбца) вершины соединены некоторым путем длины два и не соединены меньшим путем. Аналогично, $A^{\{3\}}$ содержит 1 только на тех местах, где определяемые этим местом вершины соединены путем длины три и не соединены никаким путем меньшей длины, и т.д. Таким образом, матрица $D = \sum\limits_{k = 1}^{n - 1} {k \cdot A^{\{k\}}}$ и будет искомой матрицей расстояний. Элемент $d_{ij}$ этой матрицы и будет равен расстоянию между вершинами $i$ и $j$. Расстояние между вершинами $u$ и $v$ будем также обозначать как $d(u,v)$.
Замечание. Конкретное произведение-слагаемое $a_{il_1 } a_{l_1 l_2 } ...a_{l_{k - 2} l_{k - 1} } a_{l_{k - 1} j} = 1$ элемента $a_{ij}^{(k)}$ $k$-ой степени матрицы смежности $A^k$ задает конкретный $(i,j)$-путь $i\{i,l_1\}l_1 \{l_1 ,l_2 \}l_2 ...l_{k - 2} \{l_{k - 2} ,l_{k - 1} \}l_{k - 1} \{l_{k - 1} ,j\}j$ из $i$-ой вершины в $j$-ую. Последовательность смежных вершин и соединяющих их ребер $i\{i,l_1 \}l_1 \{l_1 ,l_2 \}l_2 ...l_{k - 2} \{l_{k - 2} ,l_{k - 1} \}l_{k - 1} \{l_{k - 1} ,j\}j$ называют ещё $(i,j)$-маршрутом . Маршрут отличается от цепи, состоящей только из различных смежных ребер, ещё тем, что в маршруте допускаются равные ребра. Простой маршрут состоит из различных смежных вершин и ребер, т.е. практически совпадает с простой цепью.
Достаточно очевидно, что элемент $d_{ij} $ матрицы расстояний определяет длину минимальной цепи соединяющей $i$-ую вершину с $j$-ой.
Рассмотрим примеры графов, заданных рисунками 1 и 2, их матриц смежности и их матриц расстояний.
Рис.1 (Граф $\Gamma _1$, матрица смежности $A_1$, матрица расстояний $D_1$).
$A_1 = \left({{\begin{array}{*c}
0 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 1 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 \\
1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 1 & 0 & 0 & 1 & 1 & 1 & 0 & 1 & 0 & 0 & 1 \\
0 & 0 & 0 & 0 & 1 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 1 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 0 \\
0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 1 & 0 & 1 & 1 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 1 & 0 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 \\
0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 \\
\end{array} }} \right),
$
$D_1 = \left({{\begin{array}{*c}
2 & 1 & 1 & 1 & 2 & 3 & 3 & 3 & 3 & 2 & 3 & 3 & 2 \\
1 & 2 & 1 & 1 & 2 & 3 & 3 & 3 & 3 & 2 & 3 & 3 & 2 \\
1 & 1 & 2 & 1 & 1 & 2 & 2 & 2 & 2 & 1 & 2 & 2 & 1 \\
1 & 1 & 1 & 2 & 2 & 3 & 3 & 3 & 3 & 2 & 3 & 3 & 2 \\
2 & 2 & 1 & 2 & 2 & 1 & 1 & 1 & 2 & 1 & 2 & 2 & 1 \\
3 & 3 & 2 & 3 & 1 & 2 & 1 & 1 & 3 & 2 & 3 & 3 & 2 \\
3 & 3 & 2 & 3 & 1 & 1 & 2 & 1 & 3 & 2 & 3 & 3 & 2 \\
3 & 3 & 2 & 3 & 1 & 1 & 1 & 2 & 3 & 2 & 3 & 3 & 2 \\
3 & 3 & 2 & 3 & 2 & 3 & 3 & 3 & 2 & 1 & 1 & 1 & 2 \\
2 & 2 & 1 & 2 & 1 & 2 & 2 & 2 & 1 & 2 & 1 & 1 & 1 \\
3 & 3 & 2 & 3 & 2 & 3 & 3 & 3 & 2 & 2 & 2 & 1 & 2 \\
3 & 3 & 2 & 3 & 2 & 3 & 3 & 3 & 1 & 1 & 1 & 2 & 2 \\
2 & 2 & 1 & 2 & 1 & 2 & 2 & 2 & 2 & 1 & 2 & 2 & 2 \\
\end{array} }} \right)
$

Рис. 2 (Граф $\Gamma _2$, матрица смежности $A_2$, матрица расстояний $D_2$).
$A_2 = \left({{\begin{array}{*c}
0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 1 & 0 & 1 & 0 & 0 & 1 & 1 & 0 \\
0 & 0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 \\
\end{array} }} \right)$,
$D_2 = \left({{\begin{array}{*c}
2 & 1 & 2 & 3 & 4 & 5 & 6 & 4 & 4 & 5 \\
1 & 2 & 1 & 2 & 3 & 4 & 5 & 3 & 3 & 4 \\
2 & 1 & 2 & 1 & 2 & 3 & 4 & 2 & 2 & 3 \\
3 & 2 & 1 & 2 & 1 & 2 & 3 & 1 & 1 & 2 \\
4 & 3 & 2 & 1 & 2 & 1 & 2 & 2 & 2 & 3 \\
5 & 4 & 3 & 2 & 1 & 2 & 1 & 3 & 3 & 4 \\
6 & 5 & 4 & 3 & 2 & 1 & 2 & 4 & 4 & 5 \\
4 & 3 & 2 & 1 & 2 & 3 & 4 & 2 & 2 & 3 \\
4 & 3 & 2 & 1 & 2 & 3 & 4 & 2 & 2 & 1 \\
5 & 4 & 3 & 2 & 3 & 4 & 5 & 3 & 1 & 2 \\
\end{array} }} \right).
$
По матрицам $D_1$ и $D_2$ легко определяются диаметры $d_1$ графа $\Gamma _1$ и $d_2$ графа $\Gamma _2$, как максимальные значения элементов этих матриц. Так $d_1 = 3$, а $d_2 = 6$.
Кроме матрицы расстояний теория графов рассматривает и другие матрицы, элементы которых определяются через длину пути. Таковой, например, является матрица обходов . В матрице обходов $(i,j)$-й элемент равен длине наиболее длинного пути (наиболее длинной цепи) из $i$-ой вершины в $j$-ую, а если таких путей нет вообще, то в соответствии с определением расстояния $(i,j)$-ый элемент матрицы обходов полагается равным нулю.
О методах определения минимальной и максимальной цепей с использованием матрицы расстояний, соединяющих $i$-ую и $j$-ую вершины в графе, сделаем замечание в конце параграфа.
А сейчас приведем ещё некоторые определения теории графов, связанные с расстояниями между вершинами и которые легко определяются из матриц расстояний.
Эксцентриситет $e(v)$ вершины $v$ в связном графе $\Gamma$ определяется как max $d(u,v)$ по всем вершинам $u$ в $\Gamma$. Радиусом $r(\Gamma)$ называется наименьший из эксцентриситетов вершин. Заметим, что наибольший из эксцентриситетов равен диаметру графа. Вершина $v$ называется центральной вершиной графа $\Gamma$, если $e(v) = r(\Gamma)$; центр графа $\Gamma$ — множество всех центральных вершин.
Так для графа $\Gamma _1$ с рис.1, эксцентриситет вершины 13 будет равен 2 ($e(13) = 2$). Такие же эксцентриситеты будут иметь вершины 3, 5 и 10 ($e(3) = e(5) = e(10) = 2$). Эксцентриситет равный 2 будет наименьшим для графа $\Gamma _1$, т.е. $r(\Gamma _1) = 2$. Центр графа $\Gamma _1$ будет состоять из вершин 3, 5, 10 и 13. Наибольший эксцентриситет будет равен 3 и будет равен, как отмечалось выше, диаметру графа $\Gamma _1$.
Для графа $\Gamma _2$ с рис. 2 наименьший эксцентриситет будет иметь единственная вершина 4 ($e(4) = r(\Gamma _2) = 3$). Следовательно, центр графа $\Gamma _2$ состоит из одной вершины 4. Диаметр графа $\Gamma _2$, как отмечалось выше, равен 6.
Граф $\Gamma _2$ является деревом, а структуру центра любого дерева описывает приводимая ниже теорема.
Теорема Жордана—Сильвестра. Каждое дерево имеет центр, состоящий или из одной вершины или двух смежных вершин.
Доказательство. Обозначим через $K_1$ граф, состоящий из одной изолированной вершины, а через $K_2$ — граф — из двух вершин соединенных ребром. По определению положим $e(K_1) = r(K_1) = 0$. Тогда утверждение теоремы будет выполнено для $K_1$ и $K_2$. Покажем, что у любого дерева $T$ те же центральные вершины, что и у дерева ${T}"$, полученного из $T$ удалением всех его висячих вершин. Ясно, что расстояние от данной вершины $u$ до любой другой вершины $v$ может достигать наибольшего значения только тогда, когда $v$ — висячая вершина.
Таким образом, эксцентриситет каждой вершины дерева ${T}"$ точно на единицу меньше эксцентриситета этой же вершины в $T$. Отсюда вытекает, что вершины дерева $T$, имеющие наименьший эксцентриситет в $T$, совпадают с вершинами, имеющими наименьший эксцентриситет в ${T}"$, т.е. центры деревьев $T$ и ${T}"$ совпадают. Если процесс удаления висячих вершин продолжить, то мы получим последовательность деревьев с тем же центром, что и у $T$. В силу конечности $T$ мы обязательно придем или к $K_1$, или к $K_2$. В любом случае все вершины дерева полученного таким способом, образуют центр дерева, который, таким образом, состоит или из единственной вершины, или из двух смежных вершин. Доказательство закончено.
Покажем теперь, как с помощью матрицы расстояний можно определить, например, минимальную цепь соединяющую вершину 4 с вершиной 8 на графе $\Gamma _1$. В матрице $D_1$ элемент $d_{48} = 3$. Возьмем 8-ой столбец матрицы $D_1$ и найдем в столбце все элементы этого столбца равные 1. По крайней мере, один такой элемент найдется в силу связности графа $D_1$. На самом деле таких единиц в 8-ом столбце будет три, и расположены они в 5-ой, 6-ой и 7-ой строках. Возьмем теперь 4-ую строку и рассмотрим в ней элементы, расположенные в 5-ом, 6-ом и 7-ом столбцах. Эти элементы будут 2, 3 и 3 соответственно. Только элемент, расположенный в 5-ом столбце равен 2 и вместе с 1, расположенной на месте (5,8), дает сумму 3. Значит, вершина 5 входит в цепь $\{ \{4,?\}, \{?,5\}, \{5,8\} \}$. Возьмем теперь 5-ый столбец матрицы и рассмотрим 1 этого столбца. Это будут элементы расположенные в 3-ей, 6-й, 7-ой, 8-ой, 10-ой и 13-ой строках. Вновь возвращаемся к 4-ой строке и видим, что только на пересечении третьего столбца и 4-й строки стоит 1, что в сочетании с 1 на месте (3,5) дает в сумме 2. Следовательно, искомая цепь будет $\{ \{4,3\}, \{3,5\}, \{5,8\} \}$. Посмотрев теперь на рисунок 1, убеждаемся в справедливости найденного решения.
Хотя про матрицу обхода современные учебники говорят, что «эффективных методов для нахождения её элементов не существует», будем помнить, что с использованием матрицы инцидентности мы можем найти все цепи соединяющие пару вершин в связном графе, а значит и цепи максимальной длины.
На основе обработанных данных может быть построено несколько моделей.
Прямоугольная вещественнозначная матрица
После обработки данных получена прямоугольная вещественная матрица. Данная матрица отражает информацию о суммарной стоимости контрактов, заключенных в m регионах (напомним, что m=86) для n классов классификатора ОКПД (все контракты проведены по 62 различным кодам классификатора). Итак, полученная матрица состоит из m n-мерных векторов.
Элементы матрицы имеют сильный разброс в диапазоне от 0 до рублей. Такой большой диапазон может создать проблемы для дальнейшего анализа данных. Тем более что некоторые классификаторы являются «популярными» и по ним проводятся частые и большие объемы закупок, как, например, по классификатору с кодом 45. В то же время код классификатора 12 (Руды урановые и ториевые) содержит очень редкие закупки на небольшие суммы. В связи с вышеописанным важно каким-то образом уравнять вклад этих величин и произвести нормировку данных. Нормировка данных - это процесс изменения исходных данных и приведения их к безразмерному виду. Данный процесс приводит к повышению качества данных.
В качестве нормировки этой матрицы может быть выбран один из следующих способов: нормировка в долях от общей суммы контрактов по каждому региону, нормировка в долях от общей суммы по каждому коду классификатора, население региона.
1) Нормировка по регионам
Для любого региона нахождение доли участия каждого классификатора в формировании суммы стоимости контрактов в регионе i.
2) Нормировка по кодам классификатора
Для любого кода классификатора нахождение доли участия каждого региона в формировании суммы стоимости контрактов по кодам классификатора j.
3) Нормировка по численности регионов
Необходимо разделить каждый элемент матрицы на численность соответствующего региона.
Также можно рассмотреть стандартные способы нормирования данных :
1) Мини-максная линейная нормализация
где - минимальное и максимальное значения затрат для каждого региона i в векторе.
Эта нормализация приводит все данные к значениям в диапазоне.
2) Приведение к распределению вида N (стандартизация данных)

где матем. ожидание,
среднеквадратическое отклонение вектора.
3) Нелинейная нормализация
Этот метод основан на нелинейной связи между исходными и нормализуемыми данными. Необходимо выбрать некий массив данных, назвать его нормализированным и по нему построить функцию нормализации. Все остальные данные нормализовать в соответствии с этой функцией .
Квадратная матрица расстояний
От прямоугольной вещественной матрицы можно перейти к матрице расстояний между регионами. Это будет квадратная матрица размера. Расстояние можно вычислить по одной из нижеперечисленных метрик.
Рассмотрим самые распространённые метрики:
1) Евклидово расстояние

Самая распространённая метрика - представляет собой геометрическое расстояние в многомерном пространстве.
2) Метрика Минковского

Так называемое степенное расстояние. В данном случае r отвечает за взвешивание больших разностей расстояний, а р - за взвешивание разностей по координатам. Отметим, что при r,p=2 совпадает с расстоянием Евклида.
3) Манхэттэнская метрика

Также называется метрикой городских кварталов. Считается как средняя разность по координатам. Обычно приводит к результатом, схожим с Евклидовым расстоянием, но имеет преимущество для выборок с большими значениями выбросов.
4) Косинусное сходство
Эта мера эффективна для разреженных векторов, поскольку при подсчете учитываются только ненулевые значения. Данный метод может быть применен, если исходную вещественную матрицу преобразовать (отсечь данные по некоторому порогу) и сделать более разреженной.
5) Расстояние Хэмминга

Является частным случаем метрики Минковского и применяется для бинарных векторов. Для того чтобы применить это расстояние при подсчете матрицы расстояний в данной задачи необходимо изначальную вещественнозначную матрицу привести к бинарной (с помощью введения некоторого порога).
Граф близости
Граф близости размера выводится из матрицы расстояний по некоторому порогу или по степени вершин. Так как матрица расстояний не разрежена, то можно рассмотреть некие пороги, например, топ-5 элементов в каждой строчке (для каждого кода классификатора) или топ-5 по столбцам (для каждого региона). Таким образом можно получить разреженную матрицу, которая позволит нагляднее визуализировать результаты.
Вышеописанные модели универсальны в рамках рассматриваемой задачи.
Во-первых, они могут быть применены к данным не только за 2015, но и за любой период.
Во-вторых, используя разные срезы и различные пороги можно перейти к аналогичным матрицам, а значит, применить данную модель многократно в зависимости от различных ситуаций.
В данном разделе описаны три математические модели. Из вещественнозначной прямоугольной матрицы можно получить квадратную матрицу расстояний. В качестве меры расстояния могут быть использованы метрики, описанные выше. Из матрицы расстояний можно получить разреженный граф близости путем введения определенных порогов и(или) ограничений.





