Регрессионная статистика множественный r. Множественная линейная корреляция. Использование возможностей табличного процессора «Эксель»
При изучении сложных явлений необходимо учитывать более двух случайных факторов. Правильное представление о природе связи между этими факторами можно получить только в том случае, если подвергнуть исследованию сразу все рассматриваемые случайные факторы. Совместное изучение трех и более случайных факторов позволит исследователю установить более или менее обоснованные предположения о причинных зависимостях между изучаемыми явлениями. Простой формой множественной связи является линейная зависимость между тремя признаками. Случайные факторы обозначаются как X 1 , X 2 и X 3 . Парный коэффициенты корреляции между X 1 и X 2 обозначается как r 12 , соответственно между X 1 и X 3 - r 12 , между X 2 и X 3 - r 23 . В качестве меры тесноты линейной связи трех признаков используют множественные коэф-фициенты корреляции, обозначаемые R 1 ּ 23 , R 2 ּ 13 , R 3 ּ 12 и частные коэффициенты корреляции, обозначаемые r 12.3 , r 13.2 , r 23.1 .
Множественный коэффициент корреляции R 1.23 трех факторов - это показатель тесноты линейной связи между одним из факторов (индекс перед точкой) и совокупностью двух других факторов (индексы после точки).
Значения коэффициента R всегда находятся в пределах от 0 до 1. При приближении R к единице степень линейной связи трех признаков увеличивается.
Между коэффициентом множественной корреляции, например R 2 ּ 13 , и двумя коэффициентами парной корреляции r 12 и r 23 существует соотношение: каждый из парных коэффициентов не может превышать по абсолютной величине R 2 ּ 13 .
Формулы для вычисления множественных коэффициентов корреляции при известных значениях коэффициентов парной корреляции r 12 , r 13 и r 23 имеют вид:
Квадрат коэффициента множественной корреляции R 2 называется коэффициентом множественной детерминации. Он показывает долю вариации зависимой переменной под воздействием изучаемых факторов.
Значимость множественной корреляции оценивается по F -критерию:
![]()
n – объем выборки; k – число факторов. В нашем случае k = 3.
нулевая гипотеза о равенстве множественного коэффициента корреляции в совокупности нулю (h o
:r
=0)принимается, если f
ф <f t
, и отвергается, если
f
ф ³ f
т.
теоретическое значение f -критерия определяется для v 1 = k - 1 и v 2 = n - k степеней свободы и принятого уровня значимости a (приложение 1).
Пример вычисления коэффициента множественной корреляции . При изучении взаимосвязи между факторами были получены коэффициенты парной корреляции (n =15): r 12 ==0,6; г 13 = 0,3; r 23 = - 0,2.
Необходимо выяснить зависимость признака X 2 от признака X 1 и X 3 , т. е. рассчитать коэффициент множественной корреляции:

Табличное значение F -критерия при n 1 = 2 и n 2 = 15 – 3 = 12 степенях свободы при a = 0,05 F 0,05 = 3,89 и при a = 0,01 F 0,01 = 6,93.
Таким образом, взаимосвязь между признаками R
2.13 = 0,74 значима на
1%-ном уровне значимости F
ф > F
0,01 .
Судя по коэффициенту множественной детерминации R 2 = (0,74) 2 = 0,55, вариация признака X 2 на 55% связана с действием изучаемых факторов, а 45% вариации (1-R 2) не может быть объяснено влиянием этих переменных.
Частная линейная корреляция
Частный коэффициент корреляции - это показатель, измеряющий степень сопряженности двух признаков.
Математическая статистика позволяет установить корреляцию между двумя признаками при постоянном значении третьего, не ставя специального эксперимента, а используя парные коэффициенты корреляции r 12 , r 13 , r 23 .
Частные коэффициенты корреляции рассчитывают по формулам:

Цифры перед точкой указывают, между какими признаками изучается зависимость, а цифра после точки - влияние какого признака исключается (элиминируется). Ошибку и критерий значимости частной корреляции определяют по тем же формулам, что и парной корреляции:
 .
.
Теоретическое значение t- критерия определяется для v = n – 2 степеней свободы и принятого уровня значимости a (приложение 1).
Нулевая гипотеза о равенстве частного коэффициента корреляции в совокупности нулю (H o
: r
= 0)принимается, если t
ф < t
т, и отвергается, если
t
ф ³ t
т.
Частные коэффициенты могут принимать значения, заключенные между -1 и+1. Частные коэффициенты детерминации находят путем возведения в квадрат частных коэффициентов корреляции:
D 12.3 = r 2 12ּ3 ; d 13.2 = r 2 13ּ2 ; d 23ּ1 = r 2 23ּ1 .
Определение степени частного воздействия отдельных факторов на результативный признак при исключении (элиминировании) связи его с другими признаками, искажающими эту корреляцию, часто представляет большой интерес. Иногда бывает, что при постоянном значении элиминируемого признака нельзя подметить его статистического влияния на изменчивость других признаков. Чтобы уяснить технику расчета частного коэффициента корреляции, рассмотрим пример. Имеются три параметра X , Y и Z . Для объема выборки n = 180 определены парные коэффициенты корреляции
r xy = 0,799; r xz = 0,57; r yz = 0,507.
Определим частные коэффициенты корреляции:

Частный коэффициент корреляции между параметром X и Y Z (r хуּz = 0,720) показывает, что лишь незначительная часть взаимосвязи этих признаков в общей корреляции (r xy = 0,799) обусловлена влиянием третьего признака (Z ). Аналогичное заключение необходимо сделать и в отношении частного коэффициента корреляции между параметром X и параметром Z с постоянным значением параметраY (r х z ּу = 0,318 и r xz = 0,57). Напротив, частный коэффициент корреляции между параметрами Y и Z с постоянным значением параметра X r yz ּx = 0,105 значительно отличается от общего коэффициента корреляции r у z = 0,507. Из этого видно, что если подобрать объекты с одинаковым значением параметра X , то связь между признаками Y и Z у них будет очень слабой, так как значительная часть в этой взаимосвязи обусловлена варьированием параметра X .
При некоторых обстоятельствах частный коэффициент корреляции может оказаться противоположным по знаку парному.
Например, при изучении взаимосвязи между признаками X, У
и Z
- были получены парные коэффициенты корреляции (при n
= 100): r
ху = 0,6; r
х z
= 0,9;
r у z
= 0,4.
Частные коэффициенты корреляции при исключении влияния третьего признака:

Из примера видно, что значения парного коэффициента и частного коэффициента корреляции разнятся в знаке.
Метод частной корреляции дает возможность вычислить частный коэффициент корреляции второго порядка. Этот коэффициент указывает на взаимосвязь между первым и вторым признаком при постоянном значении третьего и четвертого. Определение частного коэффициента второго порядка ведут на основе частных коэффициентов первого порядка по формуле:

где r 12 . 4 , r 13 ּ4 , r 23 ּ4 - частные коэффициенты, значение которых определяют по формуле частного коэффициента, используя коэффициенты парной корреляции r 12 , r 13 , r 14 , r 23 , r 24 , r 34 .
ВЫВОД ИТОГОВ
| Регрессионная статистика | |
| Множественный R | 0,998364 |
| R-квадрат | 0,99673 |
| Нормированный R-квадрат | 0,996321 |
| Стандартная ошибка | 0,42405 |
| Наблюдения | 10 |
Сначала рассмотрим верхнюю часть расчетов, представленную в таблице 8.3а , - регрессионную статистику.
Величина R-квадрат , называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). Мера определенности всегда находится в пределах интервала .
В большинстве случаев значение R-квадрат находится между этими значениями, называемыми экстремальными, т.е. между нулем и единицей.
Если значение R-квадрата близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значение R-квадрата , близкое к нулю, означает плохое качество построенной модели.
В нашем примере мера определенности равна 0,99673, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным.
Множественный R - коэффициент множественной корреляции R - выражает степень зависимости независимых переменных (X) и зависимой переменной (Y).
Множественный R равен квадратному корню из коэффициента детерминации, эта величина принимает значения в интервале от нуля до единицы.
В простом линейном регрессионном анализе множественный R равен коэффициенту корреляции Пирсона. Действительно, множественный R в нашем случае равен коэффициенту корреляции Пирсона из предыдущего примера (0,998364).
| Коэффициенты | Стандартная ошибка | t-статистика | |
| Y-пересечение | 2,694545455 | 0,33176878 | 8,121757129 |
| Переменная X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * Приведен усеченный вариант расчетов | |||
Теперь рассмотрим среднюю часть расчетов, представленную в таблице 8.3б . Здесь даны коэффициент регрессии b (2,305454545) и смещение по оси ординат, т.е. константа a (2,694545455).
Исходя из расчетов, можем записать уравнение регрессии таким образом:
Y= x*2,305454545+2,694545455
Направление связи между переменными определяется на основании знаков (отрицательный или положительный) коэффициентов регрессии (коэффициента b).
Если знак при коэффициенте регрессии - положительный, связь зависимой переменной с независимой будет положительной. В нашем случае знак коэффициента регрессии положительный, следовательно, связь также является положительной.
Если знак при коэффициенте регрессии - отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
В таблице 8.3в . представлены результаты вывода остатков . Для того чтобы эти результаты появились в отчете, необходимо при запуске инструмента "Регрессия" активировать чекбокс "Остатки".
ВЫВОД ОСТАТКА
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
При помощи этой части отчета мы можем видеть отклонения каждой точки от построенной линии регрессии. Наибольшее абсолютное значение
7.1. Линейный регрессионный анализ
заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессионный анализ позволяет установить функциональную зависимость между некоторой случайной величиной Y
и некоторыми влияющими на Y
величинами X
. Такая зависимость получила название уравнения регрессии. Различают простую (y=m*x+b
) и множественную (y=m 1 *x 1 +m 2 *x 2 +... + m k *x k +b
) регрессию линейного и нелинейного типа.
Для оценки степени связи между величинами используется коэффициент множественной корреляции R Пирсона
(корреляционное отношение), который может принимать значения от 0 до 1. R
=0, если между величинами нет никакой связи, и R
=1, если между величинами имеется функциональная связь. В большинстве случаев R принимает промежуточные значения от 0 до 1. Величина R 2
называется коэффициентом детерминации
.
Задачей построения регрессионной зависимости является нахождение вектора коэффициентов M
модели множественной линейной регрессии, при котором коэффициент R
принимает максимальное значение.
Для оценки значимости R
применяется F-критерий Фишера
, вычисляемый по формуле:
Где n – количество экспериментов; k – число коэффициентов модели. Если F превышает некоторое критическое значение для данных n и k и принятой доверительной вероятности, то величина R считается существенной.
7.2. Инструмент Регрессия из Пакета анализа позволяет вычислить следующие данные:
· коэффициенты линейной функции регрессии – методом наименьших квадратов; вид функции регрессии определяется структурой исходных данных;
· коэффициент детерминации и связанные с ним величины (таблица Регрессионная статистика );
· дисперсионную таблицу и критериальную статистику для проверки значимости регрессии (таблица Дисперсионный анализ );
· среднеквадратическое отклонение и другие его статистические характеристики для каждого коэффициента регрессии , позволяющие проверить значимость этого коэффициента и построить для него доверительные интервалы;
· значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии (таблица Вывод остатка );
· вероятности, соответствующие упорядоченным по возрастанию значениям переменной Y (таблица Вывод вероятности ).
7.3. Вызовите инструмент создания выборки через Данные> Анализ данных> Регрессия .

7.4. В поле Входной интервал Y
вводится адрес диапазона, содержащего значения зависимой переменной Y. Диапазон должен состоять из одного столбца.
В поле Входной интервал X
вводится адрес диапазона, содержащего значения переменной X. Диапазон должен состоять из одного или нескольких столбцов, но не более чем из 16 столбцов. Если указанные в полях Входной интервал Y
и Входной интервал X
диапазоны включают заголовки столбцов, то необходимо установить флажок опции Метки
– эти заголовки будут использованы в выходных таблицах, сгенерированных инструментом Регрессия
.
Флажок опции Константа - ноль
следует установить, если в уравнении регрессии константа b
принудительно полагается равной нулю.
Опция Уровень надежности
устанавливается тогда, когда необходимо построить доверительные интервалы для коэффициентов регрессии с доверительным уровнем, отличным от 0.95, который используется по умолчанию. После установки флажка опции Уровень надежности
становится доступным поле ввода, в котором вводится новое значение доверительного уровня.
В области Остатки
имеются четыре опции: Остатки
, Стандартизованные остатки
, График остатков
и График подбора
. Если установлена хотя бы одна из них, то в выходных результатах появится таблица Вывод остатка
, в которой будут выведены значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии. В области Нормальная вероятность
имеется одна опция – ; ее установка порождает в выходных результатах таблицу Вывод вероятности
и приводит к построению соответствующего графика.
7.5. Установите параметры в соответствии с рисунком. Проверьте, что в качестве величины Y указана первая переменная (включая ячейку с названием), и в качестве величины X указаны две остальные переменные (включая ячейки с названиями). Нажмите OK .


7.6. В таблице Регрессионная статистика приводятся следующие данные.
Множественный R – корень из коэффициента детерминации R 2 , приведенного в следующей строке. Другое название этого показателя – индекс корреляции, или множественный коэффициент корреляции.
R-квадрат – коэффициент детерминации R 2 ; вычисляется как отношение регрессионной суммы квадратов (ячейка С12) к полной сумме квадратов (ячейка С14).
Нормированный R-квадрат вычисляется по формуле
где n – количество значений переменной Y, k – количество столбцов во входном интервале переменной X.
Стандартная ошибка – корень из остаточной дисперсии (ячейка D13).
Наблюдения – количество значений переменной Y.
7.7. В Дисперсионной таблице в столбце SS приводятся суммы квадратов, в столбце df – число степеней свободы. в столбце MS – дисперсии. В строке Регрессия в столбце f вычислено значение критериальной статистики для проверки значимости регрессии. Это значение вычисляется как отношение регрессионной дисперсии к остаточной (ячейки D12 и D13). В столбце Значимость F вычисляется вероятность полученного значения критериальной статистики. Если эта вероятность меньше, например, 0.05 (заданного уровня значимости), то гипотеза о незначимости регрессии (т.е. гипотеза о том, что все коэффициенты функции регрессии равны нулю) отвергается и считается, что регрессия значима. В данном примере регрессия незначима.
7.8. В следующей таблице, в столбце Коэффициенты
, записаны вычисленные значения коэффициентов функции регрессии, при этом в строке Y-пересечение
записано значение свободного члена b
. В столбце Стандартная ошибка
вычислены среднеквадратические отклонения коэффициентов.
В столбце t-статистика
записаны отношения значений коэффициентов к их среднеквадратическим отклонениям. Это значения критериальных статистик для проверки гипотез о значимости коэффициентов регрессии.
В столбце P-Значение
вычисляются уровни значимости, соответствующие значениям критериальных статистик. Если вычисленный уровень значимости меньше заданного уровня значимости (например, 0.05). то принимается гипотеза о значимом отличии коэффициента от нуля; в противном случае принимается гипотеза о незначимом отличии коэффициента от нуля. В данном примере только коэффициент b
значимо отличается от нуля, остальные – незначимо.
В столбцах Нижние 95%
и Верхние 95%
приводятся границы доверительных интервалов с доверительным уровнем 0.95. Эти границы вычисляются по формулам
Нижние 95% = Коэффициент - Стандартная ошибка * t α
;
Верхние 95% = Коэффициент + Стандартная ошибка * t α
.
Здесь t α
– квантиль порядка α
распределения Стьюдента с (n-k-1) степенью свободы. В данном случае α
= 0.95. Аналогично вычисляются границы доверительных интервалов в столбцах Нижние 90.0%
и Верхние 90.0%
.
7.9. Рассмотрим таблицу Вывод остатка из выходных результатов. Эта таблица появляется в выходных результатах только тогда, когда установлена хотя бы одна опция в области Остатки диалогового окна Регрессия .

В столбце Наблюдение
приводятся порядковые номера значений переменной Y
.
В столбце Предсказанное Y
вычисляются значения функции регрессии у i = f(х i) для тех значений переменной X
, которым соответствует порядковый номер i
в столбце Наблюдение
.
В столбце Остатки
содержатся разности (остатки) ε i =Y-у i , а в столбце Стандартные остатки
– нормированные остатки, которые вычисляются как отношения ε i / s ε . где s ε – среднеквадратическое отклонение остатков. Квадрат величины s ε вычисляется по формуле
![]()
где – среднее остатков. Величину можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
7.10. По значениям таблицы Вывод остатка строятся два типа графиков: графики остатков и графики подбора (если установлены соответствующие опции в области Остатки диалогового окна Регрессия ). Они строятся для каждого компонента переменной X в отдельности.
На графиках остатков отображаются остатки, т.е. разности между исходными значениями Y и вычисленными по функции регрессии для каждого значения компонента переменной X .

На графиках подбора отображаются как исходные значения Y, так и вычисленные значения функции регрессии для каждого значения компонента переменной X .

7.11. Последней таблицей выходных результатов является таблица Вывод вероятности
. Она появляется, если в диалоговом окне Регрессия
установлена опция График нормальной вероятности
.
Значения в столбце Персентиль
вычисляются следующим образом. Вычисляется шаг h = (1/n)*100%
, первое значение равно h/2
, последнее равно 100-h/2
. Начиная со второго значения каждое последующее значение равно предыдущему, к которому прибавлен шаг h
.
В столбце Y
приведены значения переменной Y
, упорядоченные по возрастанию. По данным этой таблицы строится так называемый график нормального распределения
. Он позволяет визуально оценить степень линейности зависимости между переменными X
и Y
.
8. Дисперсионный анализ
8.1. Пакет анализа
позволяет провести три вида дисперсионного анализа. Выбор конкретного инструмента определяется числом факторов и числом выборок в исследуемой совокупности данных.
используется для проверки гипотезы о сходстве средних значений двух или более выборок, принадлежащих одной и той же генеральной совокупности.
Двухфакторный дисперсионный анализ с повторениями
представляет собой более сложный вариант однофакторного анализа, включающий более чем одну выборку для каждой группы данных.
Двухфакторный дисперсионный анализ без повторения
представляет собой двухфакторный анализ дисперсии, не включающий более одной выборки на группу. Он используется для проверки гипотезы о том, что средние значения двух или нескольких выборок одинаковы (выборки принадлежат одной и той же генеральной совокупности).
8.2. Однофакторный дисперсионный анализ
8.2.1. Подготовим данные для анализа. Создайте новый лист и скопируйте на него колонки A, B, C, D . Удалите первые две строки. Подготовленные данные можно использовать для проведения Однофакторного дисперсионного анализа.


8.2.2. Вызовите инструмент создания выборки через Данные> Анализ данных> Однофакторный дисперсионный анализ. Заполните в соответствии с рисунком. Нажмите OK .


8.2.3. Рассмотрим таблицу Итоги : Счет – число повторений, Сумма – сумма значений показателя по строкам, Дисперсия – частная дисперсия показателя.
8.2.4. Таблица Дисперсионный анализ : первая колонка Источник вариации содержит наименование дисперсий, SS – сумма квадратов отклонений, df – степень свободы, MS – средний квадрат, F-критерий фактического F распределения. P-значение – вероятность того, что дисперсия, воспроизводимая уравнением, равна дисперсии остатков. Оно устанавливает вероятность того, что полученная количественная определенность взаимосвязи между факторами и результатом может считаться случайной. F-критическое – это значение F теоретического, которое впоследствии сравнивается с F фактическим.
8.2.5. Нулевая гипотеза о равенстве математических ожиданий всех выборок принимается, если выполняется неравенство F-критерий < F-критическое . эту гипотезу следует отвергнуть. В данном случае средние значения выборок – значимо различаются.
Множественный коэффициент корреляции характеризует тесноту линейной связи между одной переменной и совокупностью других рассматриваемых переменных.Особое значение имеет расчет множественного коэффициента корреляции результативного признака y с факторными x 1 , x 2 ,…, x m , формула для определения которого в общем случае имеет вид
где ∆ r – определитель корреляционной матрицы; ∆ 11 – алгебраическое дополнение элемента r yy корреляционной матрицы.
Если рассматриваются лишь два факторных признака, то для вычисления множественного коэффициента корреляции можно использовать следующую формулу:

Построение множественного коэффициента корреляции целесообразно только в том случае, когда частные коэффициенты корреляции оказались значимыми, и связь между результативным признаком и факторами, включенными в модель, действительно существует.
Коэффициент детерминации
Общая формула: R 2 = RSS/TSS=1-ESS/TSSгде RSS - объясненная сумма квадратов отклонений, ESS - необъясненная (остаточная) сумма квадратов отклонений, TSS - общая сумма квадратов отклонений (TSS=RSS+ESS)
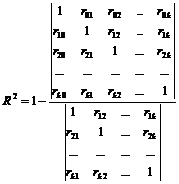 ,
,
где r ij - парные коэффициенты корреляции между регрессорами x i и x j , a r i 0 - парные коэффициенты корреляции между регрессором x i и y ;
- скорректированный (нормированный) коэффициент детерминации.
Квадрат множественного коэффициента корреляции ![]() называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
Множественный коэффициент корреляции и коэффициент детерминации изменяются в пределах от 0 до 1. Чем ближе к 1, тем связь сильнее и, соответственно, тем точнее уравнение регрессии, построенное в дальнейшем, будет описывать зависимость y
от x 1 , x 2 , …,x m . Если значение множественного коэффициента корреляции невелико (меньше 0,3), это означает, что выбранный набор факторных признаков в недостаточной мере описывает вариацию результативного признака либо связь между факторными и результативной переменными является нелинейной.
Рассчитывается множественный коэффициент корреляции с помощью калькулятора . Значимость множественного коэффициента корреляции и коэффициента детерминации проверяется с помощью критерия Фишера .
Какое из приведенных чисел может быть значением коэффициента множественной детерминации:
а) 0,4 ;
б) -1;
в) -2,7;
г) 2,7.
Множественный линейный коэффициент корреляции равен 0.75 . Какой процент вариации зависимой переменной у учтен в модели и обусловлен влиянием факторов х 1 и х 2 .
а) 56,2 (R 2 =0.75 2 =0.5625);
Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, ..., Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то естьГде I - единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов . И аналитическое решение, которое можно получить, применив этот метод, выглядит так:
где b
с крышкой - оценка вектора коэффициентов, y
- вектор значений зависимой величины, а X - матрица размера k x n+1 (n - количество предикторов, k - количество наблюдений), у которой первый столбец состоит из единиц, второй - значения первого предиктора, третий - второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:> library(faraway) > lm1<-lm(Species~Area+Elevation+Nearest+Scruz+Adjacent, data=gala) > summary(lm1) Call: lm(formula = Species ~ Area + Elevation + Nearest + Scruz + Adjacent, data = gala) Residuals: Min 1Q Median 3Q Max -111.679 -34.898 -7.862 33.460 182.584 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.068221 19.154198 0.369 0.715351 Area -0.023938 0.022422 -1.068 0.296318 Elevation 0.319465 0.053663 5.953 3.82e-06 *** Nearest 0.009144 1.054136 0.009 0.993151 Scruz -0.240524 0.215402 -1.117 0.275208 Adjacent -0.074805 0.017700 -4.226 0.000297 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 60.98 on 24 degrees of freedom Multiple R-squared: 0.7658, Adjusted R-squared: 0.7171 F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species - количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее - самое интересное - информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат:
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b
- реальный вектор коэффициентов, а эпсилон с крышкой - вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0:
где![]() - стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
- стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F - функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared:
где Yi - реальные значения Y в каждом наблюдении, Yi с крышкой - значения, предсказанные моделью, Y с чертой - среднее по всем реальным значениям Yi.![]()
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама . Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет - то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
> lm2<-lm(Species~Elevation+Adjacent, data=gala)
> summary(lm2)
Call:
lm(formula = Species ~ Elevation + Adjacent, data = gala)
Residuals:
Min 1Q Median 3Q Max
-103.41 -34.33 -11.43 22.57 203.65
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.43287 15.02469 0.095 0.924727
Elevation 0.27657 0.03176 8.707 2.53e-09 ***
Adjacent -0.06889 0.01549 -4.447 0.000134 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 60.86 on 27 degrees of freedom
Multiple R-squared: 0.7376, Adjusted R-squared: 0.7181
F-statistic: 37.94 on 2 and 27 DF, p-value: 1.434e-08
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет





