Экспоненциальное сглаживание и прогнозирование. Метод экспоненциального сглаживания. Сущность метода экспоненциального сглаживания
Экстраполяция - это метод научного исследования, который основан на распространении прошлых и настоящих тенденций, закономерностей, связей на будущее развитие объекта прогнозирования. К методам экстраполяции относятся метод скользящей средней, метод экспоненциального сглаживания, метод наименьших квадратов.
Метод экспоненциального сглаживания наиболее эффективен при разработке среднесрочных прогнозов. Он приемлем при прогнозировании только на один период вперед. Его основные достоинства простота процедуры вычислений и возможность учета весов исходной информации. Рабочая формула метода экспоненциального сглаживания:
При прогнозировании данным методом возникает два затруднения:
- выбор значения параметра сглаживания α;
- определение начального значения Uo.
От величины α зависит , как быстро снижается вес влияния предшествующих наблюдений. Чем больше α, тем меньше сказывается влияние предшествующих лет. Если значение α близко к единице, то это приводит к учету при прогнозе в основном влияния лишь последних наблюдений. Если значение α близко к нулю, то веса, по которым взвешиваются уровни временного ряда, убывают медленно, т.е. при прогнозе учитываются все (или почти все) прошлые наблюдения.
Таким образом, если есть уверенность, что начальные условия, на основании которых разрабатывается прогноз, достоверны, следует использовать небольшую величину параметра сглаживания (α→0). Когда параметр сглаживания мал, то исследуемая функция ведет себя как средняя из большого числа прошлых уровней. Если нет достаточной уверенности в начальных условиях прогнозирования, то следует использовать большую величину α, что приведет к учету при прогнозе в основном влияния последних наблюдений.
Точного метода для выбора оптимальной величины параметра сглаживания α нет. В отдельных случаях автор данного метода профессор Браун предлагал определять величину α, исходя из длины интервала сглаживания. При этом α вычисляется по формуле:
где n – число наблюдений, входящих в интервал сглаживания.
Задача выбора Uo (экспоненциально взвешенного среднего начального) решается следующими способами:
- если есть данные о развитии явления в прошлом, то можно воспользоваться средней арифметической и приравнять к ней Uo;
- если таких сведений нет, то в качестве Uo используют исходное первое значение базы прогноза У1.
Также можно воспользоваться экспертными оценками.
Отметим, что при изучении экономических временных рядов и прогнозировании экономических процессов метод экспоненциального сглаживания не всегда «срабатывает». Это обусловлено тем, что экономические временные ряды бывают слишком короткими (15-20 наблюдений), и в случае, когда темпы роста и прироста велики, данный метод не «успевает» отразить все изменения.
Пример применения метода экспоненциального сглаживания для разработки прогноза
Задача . Имеются данные, характеризующие уровень безработицы в регионе, %
- Постройте прогноз уровня безработицы в регионе на ноябрь, декабрь, январь месяцы, используя методы: скользящей средней, экспоненциального сглаживания, наименьших квадратов.
- Рассчитайте ошибки полученных прогнозов при использовании каждого метода.
- Сравните полученные результаты, сделайте выводы.
Решение методом экспоненциального сглаживания
1) Определяем значение параметра сглаживания по формуле:
где n – число наблюдений, входящих в интервал сглаживания. α = 2/ (10+1) = 0,2
2) Определяем начальное значение Uo двумя способами:
І способ (средняя арифметическая) Uo = (2,99 + 2,66 + 2,63 + 2,56 + 2,40 + 2,22 + 1,97 + 1,72 + 1,56 + 1,42)/10 = 22,13/10 = 2,21
II способ (принимаем первое значение базы прогноза) Uo = 2,99
3) Рассчитываем экспоненциально взвешенную среднюю для каждого периода, используя формулу
где t – период, предшествующий прогнозному; t+1 – прогнозный период; Ut+1 - прогнозируемый показатель; α - параметр сглаживания; Уt - фактическое значение исследуемого показателя за период, предшествующий прогнозному; Ut - экспоненциально взвешенная средняя для периода, предшествующего прогнозному.
Например:
Uфев = 2,99*0,2 +(1-0,2) * 2,21 = 2,37 (І способ)
Uмарт = 2,66*0,2+(1-0,2) * 2,37 = 2,43 (І способ) и т.д.
Uфев = 2,99*0,2 +(1-0,2) * 2,99 = 2,99 (II способ)
Uмарт = 2,66*0,2+(1-0,2) * 2,99 = 2,92 (II способ)
Uапр = 2,63*0,2+(1-0,2) * 2,92 = 2,86 (II способ) и т.д.
4) По этой же формуле вычисляем прогнозное значение
Uноябрь= 1,42*0,2+(1-0,2) * 2,08 = 1,95 (І способ)
Uноябрь= 1,42*0,2+(1-0,2) * 2,18 = 2,03 (ІІ способ)
Результаты заносим в таблицу.
5) Рассчитываем среднюю относительную ошибку по формуле:
ε = 209,58/10 = 20,96% (І способ)
ε = 255,63/10 = 25,56% (ІІ способ)
В каждом случае точность прогноза является удовлетворительной поскольку средняя относительная ошибка попадает в пределы 20-50%.
Решив данную задачу методами скользящей средней и наименьших квадратов , сделаем выводы.
к.э.н., директор по науке и развитию ЗАО "КИС"
Метод экспоненциального сглаживания
Освоение новых и анализ известных управленческих технологий, которые позволяют повысить эффективность управления бизнесом, становится особенно актуальным для российских предприятий в настоящее время. Один из наиболее популярных инструментов - система бюджетирования, которая базируется на формировании бюджета предприятия с последующим контролем исполнения. Бюджет представляет собой сбалансированные краткосрочные коммерческие, производственные, финансовые и хозяйственные планы развития организации. Бюджет предприятия содержит целевые показатели, которые рассчитываются на основании прогнозных данных. Наиболее значимым прогнозом при составлении бюджета для любого предприятия является прогноз продаж. В предыдущих статьях был проведен анализ аддитивной и мультипликативной модели и рассчитан прогнозный объем продаж на следующие периоды.
При анализе временных рядов использовался метод скользящей средней, в котором все данные независимо от периода их возникновения являются равноправными. Существует другой способ, в котором данным приписываются веса, более поздним данным придается больший вес, чем более ранним.
Метод экспоненциального сглаживания в отличие от метода скользящих средних еще и может быть использован для краткосрочных прогнозов будущей тенденции на один период вперед и автоматически корректирует любой прогноз в свете различий между фактическим и спрогнозированным результатом. Именно поэтому метод обладает явным преимуществом над ранее рассмотренным.
Название метода происходит из того факта, что при его применении получаются экспоненциально взвешенные скользящие средние по всему временному ряду. При экспоненциальном сглаживании учитываются все предшествующие наблюдения - предыдущее учитывается с максимальным весом, предшествующее ему - с несколько меньшим, самое ранее наблюдение влияет на результат с минимальным статистическим весом.
Алгоритм расчета экспоненциально сглаженных значений в любой точке ряда i основан на трех величинах :
фактическое значение Ai в данной точке ряда i,
прогноз в точке ряда Fi
некоторый заранее заданный коэффициент сглаживания W, постоянный по всему ряду.
Новый прогноз можно записать формулой:
Расчет экспоненциально сглаженных значений
При практическом использовании метода экспоненциального сглаживания возникает две проблемы: выбор коэффициента сглаживания (W), который в значительной степени влияет на результаты и определение начального условия (Fi). С одной стороны, для сглаживания случайных отклонений величину нужно уменьшать. С другой стороны, для увеличения веса новых измерений нужно увеличивать.
Хотя, в принципе, W может принимать любые значения из диапазона 0 < W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Выбор коэффициента постоянной сглаживания является субъективным. Аналитики большинства фирм при обработке рядов используют свои традиционные значения W. Так, по опубликованным данным в аналитическом отделе Kodak, традиционно используют значение 0,38, а на фирме Ford Motors - 0,28 или 0,3.
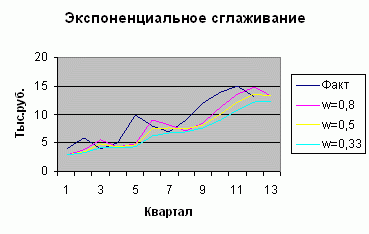
Ручной расчет экспоненциального сглаживания требует крайне большого объема монотонной работы. На примере рассчитаем прогнозный объем на 13 квартал, если имеются данные объема продаж за последние 12 кварталов, используя метод простого экспоненциального сглаживания.
Предположим, что на первый квартал прогноз продаж составил 3. И пусть коэффициент сглаживания W =0,8.
Заполним в таблице третий столбец, подставляя для каждого последующего квартала значение предыдущего по формуле:
Для 2 квартала F2 =0,8*4 (1-0,8)*3 =3,8
Для 3 квартала F3 =0,8*6 (1-0,8)*3,8 =5,6
Аналогично, рассчитывается сглаженное значение для коэффициента 0,5 и 0,33.

Расчет прогноза
объема
продаж
Прогноз объема продаж при W = 0.8 на 13 квартал составил 13.3 тыс.руб.
Эти данные можно представить в графической форме:
Насколько Forecast NOW! лучше модели Экспоненциального сглаживания (ES) вы можете увидеть на графике ниже. По оси X - номер товара, по оси Y - процентное улучшение качества прогноза. Описание модели, детальное исследование, результаты экспериментов читайте ниже.
Описание модели
Прогнозирование методом экспоненциального сглаживания является одним из самых простых способов прогнозирования. Прогноз может быть получен только на один период вперед. Если прогнозирование ведется в разрезе дней, то только на один день вперед, если недель, то на одну неделю.
Для сравнения прогнозирование проводилось на неделю вперед в течение 8 недель.
Что такое экспоненциально сглаживание?
Пусть ряд С представляет исходный ряд продаж для прогнозирования
С(1)- продажи в первую неделю, С (2) во второй и так далее.

Рисунок 1. Продажи по неделям, ряд С
Аналогично, ряд S представляет собой экспоненциально сглаженный ряд продаж. Коэффициент α находится от нуля до единицы. Получается он следующим образом, здесь t - момент времени (день, неделя)
S (t+1) = S(t) + α *(С(t) - S(t))
Большие значения константы сглаживания α ускоряют отклик прогноза на скачок наблюдаемого процесса, но могут привести к непредсказуемым выбросам, потому что сглаживание будет почти отсутствовать.
Первый раз после начала наблюдений, располагая лишь одним результатом наблюдений С (1) , когда прогноза S(1) нет и формулой (1) воспользоваться еще невозможно, в качестве прогноза S(2) следует взять С (1) .
Формула легко может быть переписана в ином виде:
S(t+1) = (1 - α)* S(t) + α * С(t) .
Таким образом, с увеличением константы сглаживания доля последних продаж увеличивается, а доля сглаженных предыдущих уменьшается.
Константа α выбирается опытным путем. Обычно строится несколько прогнозов для разных констант и выбирается наиболее оптимальная константа с точки зрения выбранного критерия.
Критерием может выступать точность прогнозирования на предыдущие периоды.
В своем исследовании мы рассмотрели модели экспоненциального сглаживания, в которых α принимает значения {0.2, 0.4, 0.6, 0.8}. Для сравнения с алгоритмом прогнозирования Forecast NOW! для каждого товара строились прогнозы при каждом α, выбирался наиболее точный прогноз. В действительности же, ситуация обстояла бы гораздо более сложная, пользователю не зная наперед точности прогноза нужно определиться с коэффициентом α, от которого очень сильно зависит качество прогноза. Вот такой замкнутый круг.
Наглядно

Рисунок 2. α =0.2 , степень экспоненциального сглаживания высокая, реальные продажи учитываются слабо

Рисунок 3. α =0.4 , степень экспоненциального сглаживания средняя, реальные продажи учитываются в средней степени
Можно видеть как с увеличением константы α сглаженный ряд все сильнее соответствует реальным продажам, и если там присутствуют выбросы или аномалии, мы получим крайне неточный прогноз.

Рисунок 4. α =0.6 , степень экспоненциального сглаживания низкая, реальные продажи учитываются значительно
Можем видеть, что при α=0.8 ряд почти в точности повторяет исходный, а значит прогноз стремится к правилу «будет продано столько же, сколько и вчера»
Стоит отметить, что здесь совершенно нельзя ориентироваться на ошибку приближения к исходным данным. Можно добиться идеального соответствия, но получить неприемлемый прогноз.

Рисунок 5. α =0.8 , степень экспоненциального сглаживания крайне низкая, реальные продажи учитываются сильно
Примеры прогнозов
Теперь давайте посмотрим на прогнозы, которые получаются с использованием различных значений α. Как можно видеть из рисунка 6 и 7, чем больше коэффициент сглаживания, тем точнее повторяет реальные продажи с опозданием на один шаг, прогноз. Такое опоздание на деле может оказаться критичным, поэтому нельзя просто выбирать максимальное значение α. Иначе получится ситуация, когда мы говорим, что будет продано ровно столько, сколько было продано в прошлый период.

Рисунок 6. Прогноз метода экспоненциального сглаживания при α=0.2

Рисунок 7. Прогноз метода экспоненциального сглаживания при α=0.6
Давайте посмотрим, что получается при α = 1.0. Напомним, S - прогнозируемые (сглаженные) продажи, C - реальные продажи.
S(t+1) = (1 - α)* S(t) + α * С(t) .
S(t+1) = С(t) .
Продажи в t+1 день согласно прогнозу равны продажам в предыдущий день. Поэтому к выбору константы надо подходить с умом.
Сравнение с Forecast NOW!
Теперь рассмотрим данный метод прогнозирования в сравнении с Forecast NOW!. Сравнение велось на 256 товарах, которые имеют различные продажи, с сезонностью краткосрочной и долгосрочной, с «плохими» продажами и дефицитом, акциями и прочими выбросами. Для каждого товара был построен прогноз по модели экспоненциального сглаживания, для различных α, выбирался лучший и сравнивался с прогнозом по модели Forecast NOW!
В таблице ниже вы видите значение ошибки прогноза для каждого товара. Ошибка здесь считалась как RMSE. Это корень из среднеквадратичного отклонения прогноза от реальности. Грубо говоря, показывает, на сколько единиц товара мы отклонились в прогнозе. Улучшение показывает, на сколько процентов прогноз Forecast NOW! лучше, если цифра положительная, и хуже, если отрицательная. На рисунке 8 по оси X отложены товары, по оси Y указано насколько прогноз Forecast NOW! лучше, чем прогнозирование методом экспоненциального сглаживания. Как можно видеть из этого графика, точность прогнозирования Forecast NOW! почти всегда в два раза выше и почти никогда не хуже. На деле это означает, что использование Forecast NOW! позволит в два раза сократить запасы или снизить дефицит.
1. Основные методические положения.
В методе простого экспоненциального сглаживания применяется взвешенное (экспоненциально) скользящее усреднение всех данных предыдущих наблюдений. Эта модель чаще всего применяется к данным, в которых необходимо оценить наличие зависимости между анализируемыми показателями (тренда) или зависимость анализируемых данных. Целью экспоненциального сглаживания является оценка текущего состояния, результаты которого определят все последующие прогнозы.
Экспоненциальное сглаживание предусматривает постоянное обновление модели за счет наиболее свежих данных. Этот метод основывается на усреднении (сглаживании) временных рядов прошлых наблюдений в нисходящем (экспоненциально) направлении. То есть более поздним событиям присваивается больший вес. Вес присваивается следующим образом: для последнего наблюдения весом будет величина α, для предпоследнего – (1-α), для того, которое было перед ним, - (1-α) 2 и т.д.
В сглаженном виде новый прогноз (для периода времени t+1) можно представлять как взвешенное среднее последнего наблюдения величины в момент времени t и ее прежнего прогноза на этот же период t. Причем вес α присваивается наблюдаемому значению, а вес (1- α) – прогнозу; при этом полагается, что 0< α<1. Это правило в общем виде можно записать следующим образом.
Новый прогноз = [α*(последнее наблюдение)]+[(1- α)*последний прогноз]
где - прогнозируемое значение на следующий период;
α – постоянная сглаживания;
Y t – наблюдение величины за текущий период t;
Прежний сглаженный прогноз этой величины на период t.
Экспоненциальное сглаживание – это процедура для постоянного пересмотра результатов прогнозирования в свете самых последних событий.
Постоянная сглаживания α является взвешенным фактором. Ее реальное значение определяется тем, в какой мере текущее наблюдение должно влиять на прогнозируемую величину. Если α близко к 1, значит в прогнозе существенно учитывается величина ошибки последнего прогнозирования. И наоборот, при малых значениях α прогнозируемая величина наиболее близка к предыдущему прогнозу. Можно представить как взвешенное среднее значение всех прошлых наблюдений с весовыми коэффициентами, экспоненциально убывающими с «возрастом» данных.
Таблица 2.1
Сравнение влияния разных значений постоянных сглаживания
Постоянная α является ключом к анализу данных. Если требуется, чтобы спрогнозированные величины были стабильны и случайные отклонения сглаживались, необходимо выбирать малое значение α. Большое значение постоянной α имеет смысл в том случае, если нужна быстрая реакция на изменения в спектре наблюдений.
2. Практический пример проведения экспоненциального сглаживания.
Представлены данные компании по объему продаж (тыс. шт.) за семь лет, постоянная сглаживания взята равной 0,1 и 0,6. Данные за 7 лет составляют тестовую часть; по ним необходимо оценить эффективность каждой из моделей. Для экспоненциального сглаживания рядов начальное значение берется равным 500 (первое значение фактических данных или среднее значение за 3 -5 периодов записывается в сглаженное значения за 2 квартал).
Таблица 2.2
Исходные данные
| Время | Действительное значение (фактическое) | Сглаженное значение | Ошибка прогноза | ||
| год | квартал | 0,1 | 0,1 | ||
| Excel | по формуле | ||||
| #Н/Д | 0,00 | ||||
| 500,00 | -150,00 | ||||
| 485,00 | 485,00 | -235,00 | |||
| 461,50 | 461,50 | -61,50 | |||
| 455,35 | 455,35 | -5,35 | |||
| 454,82 | 454,82 | -104,82 | |||
| 444,33 | 444,33 | -244,33 | |||
| 419,90 | 419,90 | -119,90 | |||
| 407,91 | 407,91 | -57,91 | |||
| 402,12 | 402,12 | -202,12 | |||
| 381,91 | 381,91 | -231,91 | |||
| 358,72 | 358,72 | 41,28 | |||
| 362,84 | 362,84 | 187,16 | |||
| 381,56 | 381,56 | -31,56 | |||
| 378,40 | 378,40 | -128,40 | |||
| 365,56 | 365,56 | 184,44 | |||
| 384,01 | 384,01 | 165,99 | |||
| 400,61 | 400,61 | -0,61 | |||
| 400,55 | 400,55 | -50,55 | |||
| 395,49 | 395,49 | 204,51 | |||
| 415,94 | 415,94 | 334,06 | |||
| 449,35 | 449,35 | 50,65 | |||
| 454,41 | 454,41 | -54,41 | |||
| 448,97 | 448,97 | 201,03 | |||
| 469,07 | 469,07 | 380,93 |
На рис. 2.1 представлен прогноз на основе экспоненциального сглаживания с постоянной сглаживания, равной 0,1.
 |
|||
Рис. 2.1. Экспоненциальное сглаживание
Решение в Excel.
1. Выберите меню «Сервис» – «Анализ данных». В списке «Инструменты анализа» выберите значение «Экспоненциальное сглаживание». Если в меню «Сервис» нет анализа данных, то необходимо установить «Пакет анализа». Для этого найти в «Параметрах» пункт «Настройки» и в появившемся диалоговом окне установить флажок на «Пакет анализа», нажать ОК.
2. На экране раскроется диалоговое окно, представленное на рис. 2.2.
3. В поле «входной интервал» введите значения исходных данных (плюс одна свободная ячейка).
4. Установите флажок «метки» (если в диапазоне ввода указаны названия столбцов).
5. Введите в поле «фактор затухания» значение (1-α).
6. В поле «входной интервал» введите значение ячейки, в которой хотели бы увидеть полученные значения.
7. Установите флажок «Опции» - «Вывод графика» для автоматического его построения.

Рис. 2.2. Диалоговое окно для экспоненциального сглаживания
3. Задание лабораторной работы.
Имеются исходные данные об объемах добычи нефтедобывающего предприятия за 2 года, представленные в таблице 2.3:
Таблица 2.3
Исходные данные
Проведите экспоненциальное сглаживание рядов. Коэффициент экспоненциального сглаживания примите равным 0,1; 0,2; 0,3. Полученные результаты прокомментируйте. Можно использовать статистические данные, представленные в приложении 1.
Выявление и анализ тенденции временного ряда часто производится с помощью его выравнивания или сглаживания. Экспоненциальное сглаживание - один из простейших и распространенных приемов выравнивания ряда. Экспоненциальное сглаживание можно представить как фильтр, на вход которого последовательно поступают члены исходного ряда, а на выходе формируются текущие значения экспоненциальной средней.
Пусть - временной ряд.
Экспоненциальное сглаживание ряда осуществляется по рекуррентной формуле: , .
Чем меньше α, тем в большей степени фильтруются, подавляются колебания исходного ряда и шума.
Если последовательно использовать рекуррентное это соотношение, то экспоненциальную среднюю можно выразить через значения временного ряда X.
Если к моменту начала сглаживания существуют более ранние данные, то в качестве начального значения можно использовать арифметическую среднюю всех имеющихся данных или какой-то их части.
После появления работ Р. Брауна экспоненциальное сглаживание часто используется для решения задачи краткосрочного прогнозирования временных рядов.
Постановка задачи
Пусть задан временной ряд: .
Необходимо решить задачу прогнозирования временного ряда, т.е. найти
Горизонт прогнозирования, необходимо, чтобы
Для того, чтобы учитывать устаревание данных, введем невозрастающую последовательность весов , тогда
Модель Брауна
Предположим, что D - невелико (краткосрочный прогноз), то для решения такой задачи используют модель Брауна .
Если рассматривать прогноз на 1 шаг вперед, то - погрешность этого прогноза, а новый прогноз получается в результате корректировки предыдущего прогноза с учетом его ошибки - суть адаптации.
При краткосрочном прогнозировании желательно как можно быстрее отразить новые изменения и в то же время как можно лучше «очистить» ряд от случайных колебаний. Т.о. следует увеличивать вес более свежих наблюдений: .
С другой стороны, для сглаживания случайных отклонений, α нужно уменьшить: .
Т.о. эти два требования находятся в противоречии. Поиск компромиссного значения α составляет задачу оптимизации модели. Обычно, α берут из интервала (0,1/3).
Примеры

Работа экспоненциального сглаживания при α=0.2 на данных ежемесячных отчетов по продажам иностранной автомобильной марки в России за период с января 2007 по октябрь 2008. Отметим резкие падения в январе и феврале, когда продажи традиционно снижаются и повышения в начале лета.
Проблемы
Модель работает только при небольшом горизонте прогнозирования. Не учитываются тренд и сезонные изменения. Чтобы учесть их влияние, предлагается использовать модели: Хольта (учитывается линейный тренд) Хольта-Уинтерса (мультипликативные экспоненциальный тренд и сезонность), Тейла-Вейджа (аддетивные линейный тренд и сезонность).





