Сумма наименьших квадратов график. Метод наименьших квадратов в Excel. Регрессионный анализ. Некоторые приложения МНК
Определение. Рангом матрицы называется максимальное число линейно независимых строк, рассматриваемых как векторы.
Теорема 1 о ранге матрицы. Рангом матрицы называется максимальный порядок отличного от нуля минора матрицы.
Понятие минора мы уже разбирали на уроке по определителям , а сейчас обобщим его. Возьмём в матрице сколько-то строк и сколько-то столбцов, причём это "сколько-то" должно быть меньше числа строк и стобцов матрицы, а для строк и столбцов это "сколько-то" должно быть одним и тем же числом. Тогда на пересечении скольки-то строк и скольки-то столбцов окажется матрица меньшего порядка, чем наша исходная матрица. Определитель это матрицы и будет минором k-го порядка, если упомянутое "сколько-то" (число строк и столбцов) обозначим через k.
Определение. Минор (r +1)-го порядка, внутри которого лежит выбранный минор r -го порядка, называется называется окаймляющим для данного минора.
Наиболее часто используются два способа отыскания ранга матрицы . Это способ окаймляющих миноров и способ элементарных преобразований (методом Гаусса).
При способе окаймляющих миноров используется следующая теорема.
Теорема 2 о ранге матрицы. Если из элементов матрицы можно составить минор r -го порядка, не равный нулю, то ранг матрицы равен r .
При способе элементарных преобразований используется следующее свойство:
Если путём элементарных преобразований получена трапециевидная матрица, эквивалентная исходной, то рангом этой матрицы является число строк в ней кроме строк, полностью состоящих из нулей.
Отыскание ранга матрицы способом окаймляющих миноров
Окаймляющим минором называется минор большего порядка по отношению к данному, если этот минорм большего порядка содержит в себе данный минор.
Например, дана матрица
Возьмём минор
окаймляющими будут такие миноры:
Алгоритм нахождения ранга матрицы следующий.
1. Находим не равные нулю миноры второго порядка. Если все миноры второго порядка равны нулю, то ранг матрицы будет равен единице (r =1 ).
2. Если существует хотя бы один минор второго порядка, не равный нулю, то составляем окаймляющие миноры третьего порядка. Если все окаймляющие миноры третьего порядка равны нулю, то ранг матрицы равен двум (r =2 ).
3. Если хотя бы один из окаймляющих миноров третьего порядка не равен нулю, то составляем окаймляющие его миноры. Если все окаймляющие миноры четвёртого порядка равны нулю, то ранг матрицы равен трём (r =2 ).
4. Продолжаем так, пока позволяет размер матрицы.
Пример 1. Найти ранг матрицы
 .
.
Решение. Минор второго порядка ![]() .
.
Окаймляем его. Окаймляющих миноров будет четыре:
 ,
,
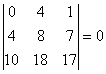 ,
,
Таким образом, все окаймляющие миноры третьего порядка равны нулю, следовательно, ранг данной матрицы равен двум (r =2 ).
Пример 2. Найти ранг матрицы
Решение. Ранг данной матрицы равен 1, так как все миноры второго порядка этой матрицы равны нулю (в этом, как и в случаях окаймляющих миноров в двух следующих примерах, дорогим студентам предлагается убедиться самостоятельно, возможно, используя правила вычисления определителей), а среди миноров первого порядка, то есть среди элементов матрицы, есть не равные нулю.
Пример 3. Найти ранг матрицы
Решение. Минор второго порядка этой матрицы , в все миноры третьего порядка этой матрицы равны нулю. Следовательно, ранг данной матрицы равен двум.
Пример 4. Найти ранг матрицы
Решение. Ранг данной матрицы равен 3, так как единственный минор третьего порядка этой матрицы равен 3.
Отыскание ранга матрицы способом элементарных преобразований (методом Гаусса)
Уже на примере 1 видно, что задача определения ранга матрицы способом окаймляющих миноров требует вычисления большого числа определителей. Существует, однако, способ, позволяющий свести объём вычислений к минимуму. Этот способ основан на использовании элементарных преобразований матриц и ещё называется также методом Гаусса.
Под элементарными преобразованиями матрицы понимаются следующие операции:
1) умножение какой-либо строки или какого либо столбца матрицы на число, отличное от нуля;
2) прибавление к элементам какой-либо строки или какого-либо столбца матрицы соответствующих элементов другой строки или столбца, умноженных на одно и то же число;
3) перемена местами двух строк или столбцов матрицы;
4) удаление "нулевых" строк, то есть таких, все элементы которых равны нулю;
5) удаление всех пропорциональных строк, кроме одной.
Теорема. При элементарном преобразовании ранг матрицы не меняется. Другими словами, если мы элементарными преобразованиями от матрицы A перешли к матрице B , то .
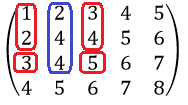
Пусть A - матрица размеров m\times n , а k - натуральное число, не превосходящее m и n : k\leqslant\min\{m;n\} . Минором k-го порядка матрицы A называется определитель матрицы k-го порядка, образованной элементами, стоящими на пересечении произвольно выбранных k строк и k столбцов матрицы A . Обозначая миноры, номера выбранных строк будем указывать верхними индексами, а выбранных столбцов - нижними, располагая их по возрастанию.
Пример 3.4. Записать миноры разных порядков матрицы
A=\begin{pmatrix}1&2&1&0\\ 0&2&2&3\\ 1&4&3&3\end{pmatrix}\!.
Решение. Матрица A имеет размеры 3\times4 . Она имеет: 12 миноров 1-го порядка, например, минор M_{{}_2}^{{}_3}=\det(a_{32})=4 ; 18 миноров 2-го порядка, например, M_{{}_{23}}^{{}^{12}}=\begin{vmatrix}2&1\\2&2\end{vmatrix}=2 ; 4 минора 3-го порядка, например,
M_{{}_{134}}^{{}^{123}}= \begin{vmatrix}1&1&0\\0&2&3\\ 1&3&3 \end{vmatrix}=0.
В матрице A размеров m\times n минор r-го порядка называется базисным , если он отличен от нуля, а все миноры (r+1)-ro порядка равны нулю или их вообще не существует.
Рангом матрицы называется порядок базисного минора. В нулевой матрице базисного минора нет. Поэтому ранг нулевой матрицы, по определению полагают равным нулю. Ранг матрицы A обозначается \operatorname{rg}A .
Пример 3.5. Найти все базисные миноры и ранг матрицы
A=\begin{pmatrix}1&2&2&0\\0&2&2&3\\0&0&0&0\end{pmatrix}\!.
Решение. Все миноры третьего порядка данной матрицы равны нулю, так как у этих определителей третья строка нулевая. Поэтому базисным может быть только минор второго порядка, расположенный в первых двух строках матрицы. Перебирая 6 возможных миноров, отбираем отличные от нуля
M_{{}_{12}}^{{}^{12}}= M_{{}_{13}}^{{}^{12}}= \begin{vmatrix}1&2\\0&2 \end{vmatrix}\!,\quad M_{{}_{24}}^{{}^{12}}= M_{{}_{34}}^{{}^{12}}= \begin{vmatrix}2&0\\2&3\end{vmatrix}\!,\quad M_{{}_{14}}^{{}^{12}}= \begin{vmatrix}1&0\\0&3\end{vmatrix}\!.
Каждый из этих пяти миноров является базисным. Следовательно, ранг матрицы равен 2.
Замечания 3.2
1. Если в матрице все миноры k-го порядка равны нулю, то равны нулю и миноры более высокого порядка. Действительно, раскладывая минор (k+1)-ro порядка по любой строке, получаем сумму произведений элементов этой строки на миноры k-го порядка, а они равны нулю.
2. Ранг матрицы равен наибольшему порядку отличного от нуля минора этой матрицы.
3. Если квадратная матрица невырожденная, то ее ранг равен ее порядку. Если квадратная матрица вырожденная, то ее ранг меньше ее порядка.
4. Для ранга применяются также обозначения \operatorname{Rg}A,~ \operatorname{rang}A,~ \operatorname{rank}A .
5. Ранг блочной матрицы определяется как ранг обычной (числовой) матрицы, т.е. не обращая внимания на ее блочную структуру. При этом ранг блочной матрицы не меньше рангов ее блоков: \operatorname{rg}(A\mid B)\geqslant\operatorname{rg}A и \operatorname{rg}(A\mid B)\geqslant\operatorname{rg}B , поскольку все миноры матрицы A (или B ) являются также минорами блочной матрицы (A\mid B) .
Теоремы о базисном миноре и о ранге матрицы
Рассмотрим основные теоремы, выражающие свойства линейной зависимости и линейной независимости столбцов (строк) матрицы.
Теорема 3.1 о базисном миноре. В произвольной матрице A каждый столбец {строка) является линейной комбинацией столбцов (строк), в которых расположен базисный минор.
Действительно, без ограничения общности предполагаем, что в матрице A размеров m\times n базисный минор расположен в первых r строках и первых r столбцах. Рассмотрим определитель
D=\begin{vmatrix}~ a_{11}&\cdots&a_{1r}\!\!&\vline\!\!&a_{1k}~\\ ~\vdots&\ddots &\vdots\!\!&\vline\!\!&\vdots~\\ ~a_{r1}&\cdots&a_{rr}\!\!&\vline\!\!&a_{rk}~\\\hline ~a_{s1}&\cdots&a_{sr}\!\!&\vline\!\!&a_{sk}~\end{vmatrix},
который получен приписыванием к базисному минору матрицы A соответствующих элементов s-й строки и k-го столбца. Отметим, что при любых 1\leqslant s\leqslant m и этот определитель равен нулю. Если s\leqslant r или k\leqslant r , то определитель D содержит две одинаковых строки или два одинаковых столбца. Если же s>r и k>r , то определитель D равен нулю, так как является минором (r+l)-ro порядка. Раскладывая определитель по последней строке, получаем
a_{s1}\cdot D_{r+11}+\ldots+ a_{sr}\cdot D_{r+1r}+a_{sk}\cdot D_{r+1\,r+1}=0,
где D_{r+1\,j} - алгебраические дополнения элементов последней строки. Заметим, что D_{r+1\,r+1}\ne0 , так как это базисный минор. Поэтому
a_{sk}=\lambda_1\cdot a_{s1}+\ldots+\lambda_r\cdot a_{sr} , где \lambda_j=-\frac{D_{r+1\,j}}{D_{r+1\,r+1}},~j=1,2,\ldots,r.
Записывая последнее равенство для s=1,2,\ldots,m , получаем
\begin{pmatrix}a_{1k}\\\vdots\\a_{mk}\end{pmatrix}= \lambda_1\cdot\! \begin{pmatrix}a_{11}\\\vdots\\a_{m1}\end{pmatrix}+\ldots \lambda_r\cdot\! \begin{pmatrix}a_{1r}\\\vdots\\a_{mr}\end{pmatrix}\!.
т.е. k -й столбец (при любом 1\leqslant k\leqslant n ) есть линейная комбинация столбцов базисного минора, что и требовалось доказать.
Теорема о базисном миноре служит для доказательства следующих важных теорем.
Условие равенства нулю определителя
Теорема 3.2 (необходимое и достаточное условие равенства нулю определителя). Для того чтобы определитель был равен нулю необходимо и достаточно, чтобы один из его столбцов {одна из его строк) был линейной комбинацией остальных столбцов (строк).
В самом деле, необходимость следует из теоремы о базисном миноре. Если определитель квадратной матрицы n-го порядка равен нулю, то ее ранг меньше n , т.е. хотя бы один столбец не входит в базисный минор. Тогда этот выбранный столбец по теореме 3.1 является линейной комбинацией столбцов, в которых расположен базисный минор. Добавляя, при необходимости, к этой комбинации другие столбцы с нулевыми коэффициентами, получаем, что выбранный столбец есть линейная комбинация остальных столбцов матрицы. Достаточность следует из свойств определителя. Если, например, последний столбец A_n определителя \det(A_1~A_2~\cdots~A_n) линейно выражается через остальные
A_n=\lambda_1\cdot A_1+\lambda_2\cdot A_2+\ldots+\lambda_{n-1}\cdot A_{n-1},
то прибавляя к A_n столбец A_1 , умноженный на (-\lambda_1) , затем столбец A_2 , умноженный на (-\lambda_2) , и т.д. столбец A_{n-1} , умноженный на (-\lambda_{n-1}) , получим определитель \det(A_1~\cdots~A_{n-1}~o) с нулевым столбцом, который равен нулю (свойство 2 определителя).
Инвариантность ранга матрицы при элементарных преобразованиях
Теорема 3.3 (об инвариантности ранга при элементарных преобразованиях). При элементарных преобразованиях столбцов (строк) матрицы ее ранг не меняется.
Действительно, пусть . Предположим, что в результате одного элементарного преобразования столбцов матрицы A получили матрицу A" . Если было выполнено преобразование I типа (перестановка двух столбцов), то любой минор (r+l)-ro порядка матрицы A" либо равен соответствующему минору (r+l)-ro порядка матрицы A , либо отличается от него знаком (свойство 3 определителя). Если было выполнено преобразование II типа (умножение столбца на число \lambda\ne0 ), то любой минор (г+l)-ro порядка матрицы A" либо равен соответствующему минору (r+l)-ro порядка матрицы A , либо отличается от него множителем \lambda\ne0 (свойство 6 определителя). Если было выполнено преобразование III типа (прибавление к одному столбцу другого столбца, умноженного на число \Lambda ), то любой минор (г+1)-го порядка матрицы A" либо равен соответствующему минору (г+1) -го порядка матрицы A (свойство 9 определителя), либо равен сумме двух миноров (r+l)-ro порядка матрицы A (свойство 8 определителя). Поэтому при элементарном преобразовании любого типа все миноры (r+l)-ro порядка матрицы A" равны нулю, так как равны нулю все миноры (г+l)-ro порядка матрицы A . Таким образом, доказано, что при элементарных преобразованиях столбцов ранг матрицы не может увеличиться. Так как преобразования, обратные к элементарным, являются элементарными, то ранг матрицы при элементарных преобразованиях столбцов не может и уменьшиться, т.е. не изменяется. Аналогично доказывается, что ранг матрицы не изменяется при элементарных преобразованиях строк.
Следствие 1. Если одна строка (столбец) матрицы является линейной комбинацией других ее строк (столбцов), то эту строку (столбец) можно вычеркнуть из матрицы, не изменив при этом ее ранга.
Действительно, такую строку при помощи элементарных преобразований можно сделать нулевой, а нулевая строка не может входить в базисный минор.
Следствие 2. Если матрица приведена к простейшему виду (1.7), то
\operatorname{rg}A=\operatorname{rg}\Lambda=r\,.
Действительно, матрица простейшего вида (1.7) имеет базисный минор r-го порядка.
Следствие 3. Любая невырожденная квадратная матрица является элементарной, другими словами, любая невырожденная квадратная матрица эквивалентна единичной матрице того же порядка.
Действительно, если A - невырожденная квадратная матрица n-го порядка, то \operatorname{rg}A=n (см. п.З замечаний 3.2). Поэтому, приводя элементарными преобразованиями матрицу A к простейшему виду (1.7), получим единичную матрицу \Lambda=E_n , так как \operatorname{rg}A=\operatorname{rg}\Lambda=n (см. следствие 2). Следовательно, матрица A эквивалентна единичной матрице E_n и может быть получена из нее в результате конечного числа элементарных преобразований. Это означает, что матрица A элементарная.
Теорема 3.4 (о ранге матрицы). Ранг матрицы равен максимальному числу линейно независимых строк этой матрицы.
В самом деле, пусть \operatorname{rg}A=r
. Тогда в матрице A
имеется r
линейно независимых строк. Это строки, в которых расположен базисный минор. Если бы они были линейно зависимы, то этот минор был бы равен нулю по теореме 3.2, а ранг матрицы A
не равнялся бы r
. Покажем, что r
- максимальное число линейно независимых строк, т.е. любые p
строк линейно зависимы при p>r
. Действительно, образуем из этих p
строк матрицу B
. Поскольку матрица B
- это часть матрицы A
, то \operatorname{rg}B\leqslant \operatorname{rg}A=r Значит, хотя бы одна строка матрицы B
не входит в базисный минор этой матрицы. Тогда по теореме о базисном миноре она равна линейной комбинации строк, в которых расположен базисный минор. Следовательно, строки матрицы B
линейно зависимы. Таким образом, в матрице A
не более, чем r
линейно независимых строк. Следствие 1.
Максимальное число линейно независимых строк в матрице равно максимальному числу линейно независимых столбцов:
\operatorname{rg}A=\operatorname{rg}A^T.
Это утверждение вытекает из теоремы 3.4, если ее применить к строкам транспонированной матрицы и учесть, что при транспонировании миноры не изменяются (свойство 1 определителя). Следствие 2.
При элементарных преобразованиях строк матрицы линейная зависимость (или линейная независимость) любой системы столбцов этой матрицы сохраняется.
В самом деле, выберем любые k
столбцов данной матрицы A
и составим из них матрицу B
. Пусть в результате элементарных преобразований строк матрицы A
была получена матрица A"
, а в результате тех же преобразований строк матрицы B
была получена матрица B"
. По теореме 3.3 \operatorname{rg}B"=\operatorname{rg}B
. Следовательно, если столбцы матрицы B
были линейно независимы, т.е. k=\operatorname{rg}B
(см. следствие 1), то и столбцы матрицы B"
также линейно независимы, так как k=\operatorname{rg}B"
. Если столбцы матрицы B
были линейно зависимы (k>\operatorname{rg}B)
, то и столбцы матрицы B"
также линейно зависимы (k>\operatorname{rg}B")
. Следовательно, для любых столбцов матрицы A
линейная зависимость или линейная независимость сохраняется при элементарных преобразованиях строк. Замечания 3.3
1.
В силу следствия 1 теоремы 3.4 свойство столбцов, указанное в следствии 2, справедливо и для любой системы строк матрицы, если элементарные преобразования выполняются только над ее столбцами. 2.
Следствие 3 теоремы 3.3 можно уточнить следующим образом: любую невырожденную квадратную матрицу, используя элементарные преобразования только ее строк (либо только ее столбцов), можно привести к единичной матрице того же порядка.
В самом деле, используя только элементарные преобразования строк, любую матрицу A
можно привести к упрощенному виду \Lambda
(рис. 1.5) (см. теорему 1.1). Поскольку матрица A
невырожденная (\det{A}\ne0)
, то ее столбцы линейно независимы. Значит, столбцы матрицы \Lambda
также линейно независимы (следствие 2 теоремы 3.4). Поэтому упрощенный вид \Lambda
невырожденной матрицы A
совпадает с ее простейшим видом (рис. 1.6) и представляет собой единичную матрицу \Lambda=E
(см. следствие 3 теоремы 3.3). Таким образом, преобразовывая только строки невырожденной матрицы, ее можно привести к единичной. Аналогичные рассуждения справедливы и для элементарных преобразований столбцов невырожденной матрицы. Теорема 3.5 (о ранге произведения матриц).
Ранге произведения и суммы матриц
\operatorname{rg}(A\cdot B)\leqslant \min\{\operatorname{rg}A,\operatorname{rg}B\}.
В самом деле, пусть матрицы A и B имеют размеры m\times p и p\times n . Припишем к матрице A матрицу C=AB\colon\,(A\mid C) . Разумеется, что \operatorname{rg}C\leqslant\operatorname{rg}(A\mid C) , так как C - это часть матрицы (A\mid C) (см. п.5 замечаний 3.2). Заметим, что каждый столбец C_j , согласно операции умножения матриц, является линейной комбинацией столбцов A_1,A_2,\ldots,A_p матрицы A=(A_1~\cdots~A_p):
C_{j}=A_1\cdot b_{1j}+A_2\cdot b_{2j}+\ldots+A_{p}\cdot b_pj},\quad j=1,2,\ldots,n.
Такой столбец можно вычеркнуть из матрицы (A\mid C) , при этом ее ранг не изменится (следствие 1 теоремы 3.3). Вычеркивая все столбцы матрицы C , получаем: \operatorname{rg}(A\mid C)=\operatorname{rg}A . Отсюда, \operatorname{rg}C\leqslant\operatorname{rg}(A\mid C)=\operatorname{rg}A . Аналогично можно доказать, что одновременно выполняется условие \operatorname{rg}C\leqslant\operatorname{rg}B , и сделать вывод о справедливости теоремы.
Следствие. Если A невырожденная квадратная матрица, то \operatorname{rg}(AB)= \operatorname{rg}B и \operatorname{rg}(CA)=\operatorname{rg}C , т.е. ранг матрицы не изменяется приумножении ее слева или справа на невырожденную квадратную матрицу.
Теорема 3.6 о ранге суммы матриц. Ранг суммы матриц не превышает суммы рангов слагаемых:
\operatorname{rg}(A+B)\leqslant \operatorname{rg}A+\operatorname{rg}B.
Действительно, составим матрицу (A+B\mid A\mid B) . Заметим, что каждый столбец матрицы A+B есть линейная комбинация столбцов матриц A и B . Поэтому \operatorname{rg}(A+B\mid A\mid B)= \operatorname{rg}(A\mid B) . Учитывая, что количество линейно независимых столбцов в матрице (A\mid B) не превосходит \operatorname{rg}A+\operatorname{rg}B , a \operatorname{rg}(A+B)\leqslant \operatorname{rg}(A+B\mid A\mid B) (см. п.5 замечаний 3.2), получаем доказываемое неравенство.
Для того что бы вычислить ранг матрицы можно применить метод окаймляющих миноров или метод Гаусса . Рассмотрим метод Гаусса или метод элементарных преобразований.
Рангом матрицы называют максимальный порядок её миноров, среди которых есть хотя бы один, не равный нулю.
Рангом системы строк (столбцов) называется максимальное количество линейно независимых строк (столбцов) этой системы.
Алгоритм нахождения ранга матрицы методом окаймляющих миноров:
- Минор M k-того порядка не равен нулю.
- Если окаймляющие миноры для минора M (k+1)-го порядка, составить невозможно (т.е. матрица содержит k строк или k столбцов), то ранг матрицы равен k . Если окаймляющие миноры существуют и все равны нулю, то ранг равен k. Если среди окаймляющих миноров есть хотя бы один, не равный нулю, то пробуем составить новый минор k+2 и т.д.
Разберем алгоритм более подробно. Сначала рассмотрим миноры первого (элементы матрицы) порядка матрицы A . Если все они равны нулю, то rangA = 0 . Если есть миноры первого порядка (элементы матрицы) не равные нулю M 1 ≠ 0 , то ранг rangA ≥ 1 .
M 1 . Если такие миноры есть, то они буду миноры второго порядка. Если все миноры окаймляющие минор M 1 равны нулю, то rangA = 1 . Если есть хоть один минор второго порядка не равные нулю M 2 ≠ 0 , то ранг rangA ≥ 2 .
Проверим есть ли окаймляющие миноры для минора M 2 . Если такие миноры есть, то они буду миноры третьего порядка. Если все миноры окаймляющие минор M 2 равны нулю, то rangA = 2 . Если есть хоть один минор третьего порядка не равные нулю M 3 ≠ 0 , то ранг rangA ≥ 3 .
Проверим есть ли окаймляющие миноры для минора M 3 . Если такие миноры есть, то они буду миноры четвертого порядка. Если все миноры окаймляющие минор M 3 равны нулю, то rangA = 3 . Если есть хоть один минор четвертого порядка не равные нулю M 4 ≠ 0 , то ранг rangA ≥ 4 .
Проверяем есть ли окаймляющий минор для минора M 4 , и так далее. Алгоритм прекращается, если на каком-то этапе окаймляющие миноры равны нулю или окаймляющий минор нельзя получить (в матрице "закончились" строки или столбцы). Порядок не нулевого минора, который получилось составить будет рангом матрицы.
Пример
Рассмотрим данный метод на примере. Дана матрицы 4х5:
У данной матрице ранг не может быть больше 4. Так же у этой матрице есть не нулевые элементы (минор первого порядка), значит ранг матрицы ≥ 1.
Составим минор 2-ого порядка. Начнем с угла.


Так определитель равен нулю, составим другой минор.

Найдем определитель данного минора.

Определить данного минора равен -2 . Значит ранг матрицы ≥ 2 .
Если данный минор был равен 0, то составили бы другие миноры. До конца бы составили все миноры по 1 и второй строке. Потом по 1 и 3 строке, по 2 и 3 строке, по 2 и 4 строке, пока не нашли бы минор не равный 0, например:

Если все миноры второго порядка равны 0, то ранг матрицы был бы равен 1. Решение можно было бы остановить.
3-го порядка.

Минор получился не нулевой. значит ранг матрицы ≥ 3 .
Если бы данный минор был нулевым, то нужно было бы составить другие миноры. Например:

Если все миноры третьего порядка равны 0, то ранг матрицы был бы равен 2. Решение можно было бы остановить.
Продолжим поиска ранга матрицы. Составим минор 4-го порядка.

Найдем определитель этого минора.

Определитель минора получился равный 0 . Построим другой минор.

Найдем определитель этого минора.

Минор получился равным 0 .
Построить минор 5-го порядка не получится, для этого нет строки в данной матрицы. Последний минор не равный нулю был 3-го порядка, значит ранг матрицы равен 3 .
Он имеет множество применений, так как позволяет осуществлять приближенное представление заданной функции другими более простыми. МНК может оказаться чрезвычайно полезным при обработке наблюдений, и его активно используют для оценки одних величин по результатам измерений других, содержащих случайные ошибки. Из этой статьи вы узнаете, как реализовать вычисления по методу наименьших квадратов в Excel.
Постановка задачи на конкретном примере
Предположим, имеются два показателя X и Y. Причем Y зависит от X. Так как МНК интересует нас с точки зрения регрессионного анализа (в Excel его методы реализуются с помощью встроенных функций), то стоит сразу же перейти к рассмотрению конкретной задачи.
Итак, пусть X — торговая площадь продовольственного магазина, измеряемая в квадратных метрах, а Y — годовой товарооборот, определяемый в миллионах рублей.
Требуется сделать прогноз, какой товарооборот (Y) будет у магазина, если у него та или иная торговая площадь. Очевидно, что функция Y = f (X) возрастающая, так как гипермаркет продает больше товаров, чем ларек.
Несколько слов о корректности исходных данных, используемых для предсказания
Допустим, у нас есть таблица, построенная по данным для n магазинов.
Согласно математической статистике, результаты будут более-менее корректными, если исследуются данные по хотя бы 5-6 объектам. Кроме того, нельзя использовать «аномальные» результаты. В частности, элитный небольшой бутик может иметь товарооборот в разы больший, чем товарооборот больших торговых точек класса «масмаркет».
Суть метода
Данные таблицы можно изобразить на декартовой плоскости в виде точек M 1 (x 1 , y 1), … M n (x n , y n). Теперь решение задачи сведется к подбору аппроксимирующей функции y = f (x), имеющей график, проходящий как можно ближе к точкам M 1, M 2, .. M n .
Конечно, можно использовать многочлен высокой степени, но такой вариант не только труднореализуем, но и просто некорректен, так как не будет отражать основную тенденцию, которую и нужно обнаружить. Самым разумным решением является поиск прямой у = ax + b, которая лучше всего приближает экспериментальные данные, a точнее, коэффициентов - a и b.
Оценка точности
При любой аппроксимации особую важность приобретает оценка ее точности. Обозначим через e i разность (отклонение) между функциональными и экспериментальными значениями для точки x i , т. е. e i = y i - f (x i).
Очевидно, что для оценки точности аппроксимации можно использовать сумму отклонений, т. е. при выборе прямой для приближенного представления зависимости X от Y нужно отдавать предпочтение той, у которой наименьшее значение суммы e i во всех рассматриваемых точках. Однако, не все так просто, так как наряду с положительными отклонениями практически будут присутствовать и отрицательные.
Решить вопрос можно, используя модули отклонений или их квадраты. Последний метод получил наиболее широкое распространение. Он используется во многих областях, включая регрессионный анализ (в Excel его реализация осуществляется с помощью двух встроенных функций), и давно доказал свою эффективность.
Метод наименьших квадратов
В Excel, как известно, существует встроенная функция автосуммы, позволяющая вычислить значения всех значений, расположенных в выделенном диапазоне. Таким образом, ничто не помешает нам рассчитать значение выражения (e 1 2 + e 2 2 + e 3 2 + ... e n 2).
В математической записи это имеет вид:

Так как изначально было принято решение об аппроксимировании с помощью прямой, то имеем:

Таким образом, задача нахождения прямой, которая лучше всего описывает конкретную зависимость величин X и Y, сводится к вычислению минимума функции двух переменных:

Для этого требуется приравнять к нулю частные производные по новым переменным a и b, и решить примитивную систему, состоящую из двух уравнений с 2-мя неизвестными вида:

После нехитрых преобразований, включая деление на 2 и манипуляции с суммами, получим:

Решая ее, например, методом Крамера, получаем стационарную точку с некими коэффициентами a * и b * . Это и есть минимум, т. е. для предсказания, какой товарооборот будет у магазина при определенной площади, подойдет прямая y = a * x + b * , представляющая собой регрессионную модель для примера, о котором идет речь. Конечно, она не позволит найти точный результат, но поможет получить представление о том, окупится ли покупка в кредит магазина конкретной площади.
Как реализоавать метод наименьших квадратов в Excel
В "Эксель" имеется функция для расчета значения по МНК. Она имеет следующий вид: «ТЕНДЕНЦИЯ» (известн. значения Y; известн. значения X; новые значения X; конст.). Применим формулу расчета МНК в Excel к нашей таблице.
Для этого в ячейку, в которой должен быть отображен результат расчета по методу наименьших квадратов в Excel, введем знак «=» и выберем функцию «ТЕНДЕНЦИЯ». В раскрывшемся окне заполним соответствующие поля, выделяя:
- диапазон известных значений для Y (в данном случае данные для товарооборота);
- диапазон x 1 , …x n , т. е. величины торговых площадей;
- и известные, и неизвестные значения x, для которого нужно выяснить размер товарооборота (информацию об их расположении на рабочем листе см. далее).
Кроме того, в формуле присутствует логическая переменная «Конст». Если ввести в соответствующее ей поле 1, то это будет означать, что следует осуществить вычисления, считая, что b = 0.
Если нужно узнать прогноз для более чем одного значения x, то после ввода формулы следует нажать не на «Ввод», а нужно набрать на клавиатуре комбинацию «Shift» + «Control»+ «Enter» («Ввод»).
Некоторые особенности
Регрессионный анализ может быть доступен даже чайникам. Формула Excel для предсказания значения массива неизвестных переменных — «ТЕНДЕНЦИЯ» — может использоваться даже теми, кто никогда не слышал о методе наименьших квадратов. Достаточно просто знать некоторые особенности ее работы. В частности:
- Если расположить диапазон известных значений переменной y в одной строке или столбце, то каждая строка (столбец) с известными значениями x будет восприниматься программой в качестве отдельной переменной.
- Если в окне «ТЕНДЕНЦИЯ» не указан диапазон с известными x, то в случае использования функции в Excel программа будет рассматривать его как массив, состоящий из целых чисел, количество которых соответствует диапазону с заданными значениями переменной y.
- Чтобы получить на выходе массив «предсказанных» значений, выражение для вычисления тенденции нужно вводить как формулу массива.
- Если не указаны новые значения x, то функция «ТЕНДЕНЦИЯ» считает их равным известным. Если и они не заданы, то в качестве аргумента берется массив 1; 2; 3; 4;…, который соразмерен диапазону с уже заданными параметрами y.
- Диапазон, содержащий новые значения x должен состоять из такого же или большего количества строк или столбцов, как диапазон с заданными значениями y. Иными словами он должен быть соразмерным независимым переменным.
- В массиве с известными значениями x может содержаться несколько переменных. Однако если речь идет лишь об одной, то требуется, чтобы диапазоны с заданными значениями x и y были соразмерны. В случае нескольких переменных нужно, чтобы диапазон с заданными значениями y вмещался в одном столбце или в одной строке.

Функция «ПРЕДСКАЗ»
Реализуется с помощью нескольких функций. Одна из них называется «ПРЕДСКАЗ». Она аналогична «ТЕНДЕНЦИИ», т. е. выдает результат вычислений по методу наименьших квадратов. Однако только для одного X, для которого неизвестно значение Y.
Теперь вы знаете формулы в Excel для чайников, позволяющие спрогнозировать величину будущего значения того или иного показателя согласно линейному тренду.
3. Аппроксимация функций с помощью метода
наименьших квадратов
Метод наименьших квадратов применяется при обработке результатов эксперимента для аппроксимации (приближения) экспериментальных данных аналитической формулой. Конкретный вид формулы выбирается, как правило, из физических соображений. Такими формулами могут быть:
![]()
![]()
и другие.
Сущность метода наименьших квадратов состоит в следующем. Пусть результаты измерений представлены таблицей:
|
Таблица 4 |
||||
|
x n |
||||
|
y n |
||||
|
(3.1) |
где f - известная функция, a 0 , a 1 , …, a m - неизвестные постоянные параметры, значения которых надо найти. В методе наименьших квадратов приближение функции (3.1) к экспериментальной зависимости считается наилучшим, если выполняется условие
|
(3.2) |
то есть сумм a квадратов отклонений искомой аналитической функции от экспериментальной зависимости должна быть минимальна .
Заметим, что функция Q называется невязкой.

Так как невязка

то она имеет минимум. Необходимым условием минимума функции нескольких переменных является равенство нулю всех частных производных этой функции по параметрам. Таким образом, отыскание наилучших значений параметров аппроксимирующей функции (3.1), то есть таких их значений, при которых Q = Q (a 0 , a 1 , …, a m ) минимальна, сводится к решению системы уравнений:
|
(3.3) |
Методу наименьших квадратов можно дать следующее геометрическое истолкование: среди бесконечного семейства линий данного вида отыскивается одна линия, для которой сумма квадратов разностей ординат экспериментальных точек и соответствующих им ординат точек, найденных по уравнению этой линии, будет наименьшей.
Нахождение параметров линейной функции
Пусть экспериментальные данные надо представить линейной функцией:
Требуется подобрать такие значения a и b , для которых функция
|
(3.4) |
будет минимальной. Необходимые условия минимума функции (3.4) сводятся к системе уравнений:
|
|

После преобразований получаем систему двух линейных уравнений с двумя неизвестными:
|
|
(3.5) |

решая которую , находим искомые значения параметров a и b .
Нахождение параметров квадратичной функции
Если аппроксимирующей функцией является квадратичная зависимость
то её параметры a , b , c находят из условия минимума функции:
|
(3.6) |
Условия минимума функции (3.6) сводятся к системе уравнений:
|
|

После преобразований получаем систему трёх линейных уравнений с тремя неизвестными:
|
|
(3.7) |

при решении которой находим искомые значения параметров a , b и c .
Пример . Пусть в результате эксперимента получена следующая таблица значений x и y :
|
Таблица 5 |
||||||||
|
y i |
0,705 |
0,495 |
0,426 |
0,357 |
0,368 |
0,406 |
0,549 |
0,768 |
Требуется аппроксимировать экспериментальные данные линейной и квадратичной функциями.
Решение. Отыскание параметров аппроксимирующих функций сводится к решению систем линейных уравнений (3.5) и (3.7). Для решения задачи воспользуемся процессором электронных таблиц Excel .
1. Сначала сцепим листы 1 и 2. Занесём экспериментальные значения x i и y i в столбцы А и В, начиная со второй строки (в первой строке поместим заголовки столбцов). Затем для этих столбцов вычислим суммы и поместим их в десятой строке.
В столбцах C – G разместим соответственно вычисление и суммирование
2. Расцепим листы.Дальнейшие вычисления проведём аналогичным образом для линейной зависимости на Листе 1и для квадратичной зависимости на Листе 2.
3. Под полученной таблицей сформируем матрицу коэффициентов и вектор-столбец свободных членов. Решим систему линейных уравнений по следующему алгоритму:
Для вычисления обратной матрицы и перемножения матриц воспользуемся Мастером функций и функциями МОБР и МУМНОЖ .
4. В блоке ячеек H2: H 9 на основе полученных коэффициентов вычислим значенияаппроксимирующего полинома y i выч ., в блоке I 2: I 9 – отклонения D y i = y i эксп . - y i выч .,в столбце J – невязку:
Полученные таблицы и построенные с помощью Мастера диаграмм графики приведёны на рисунках6, 7, 8.

Рис. 6. Таблица вычисления коэффициентов линейной функции,
аппроксимирующей экспериментальные данные.

Рис. 7. Таблица вычисления коэффициентов квадратичной функции,
аппроксимирующей экспериментальные данные.

Рис. 8. Графическое представление результатов аппроксимации
экспериментальных данных линейной и квадратичной функциями.
Ответ. Аппроксимировали экспериментальные данные линейной зависимостью y = 0,07881 x + 0,442262 c невязкой Q = 0,165167 и квадратичной зависимостью y = 3,115476 x 2 – 5,2175 x + 2,529631 c невязкой Q = 0,002103 .
Задания. Аппроксимировать функцию, заданную таблично, линейной и квадратичной функциями.
|
Таблица 6 |
|||||||||
|
№0 |
x |
0,1 |
0,2 |
0,3 |
0,4 |
0,5 |
0,6 |
0,7 |
0,8 |
|
y |
3,030 |
3,142 |
3,358 |
3,463 |
3,772 |
3,251 |
3,170 |
3,665 |
|
|
№ 1 |
|||||||||
|
3,314 |
3,278 |
3,262 |
3,292 |
3,332 |
3,397 |
3,487 |
3,563 |
||
|
№ 2 |
|||||||||
|
1,045 |
1,162 |
1,264 |
1,172 |
1,070 |
0,898 |
0,656 |
0,344 |
||
|
№ 3 |
|||||||||
|
6,715 |
6,735 |
6,750 |
6,741 |
6,645 |
6,639 |
6,647 |
6,612 |
||
|
№ 4 |
|||||||||
|
2,325 |
2,515 |
2,638 |
2,700 |
2,696 |
2,626 |
2,491 |
2,291 |
||
|
№ 5 |
|||||||||
|
1.752 |
1,762 |
1,777 |
1,797 |
1,821 |
1,850 |
1,884 |
1,944 |
||
|
№ 6 |
|||||||||
|
1,924 |
1,710 |
1,525 |
1,370 |
1,264 |
1,190 |
1,148 |
1,127 |
||
|
№ 7 |
|||||||||
|
1,025 |
1,144 |
1,336 |
1,419 |
1,479 |
1,530 |
1,568 |
1,248 |
||
|
№ 8 |
|||||||||
|
5,785 |
5,685 |
5,605 |
5,545 |
5,505 |
5,480 |
5,495 |
5,510 |
||
|
№ 9 |
|||||||||
|
4,052 |
4,092 |
4,152 |
4,234 |
4,338 |
4,468 |
4,599 |
Популярное | ||





